

SEOs have been trying to outsmart Google for as long as it has existed. Sometimes, they win; other times, their attempts fail.
Here are 10 extraordinary examples of websites that failed to fool Google.
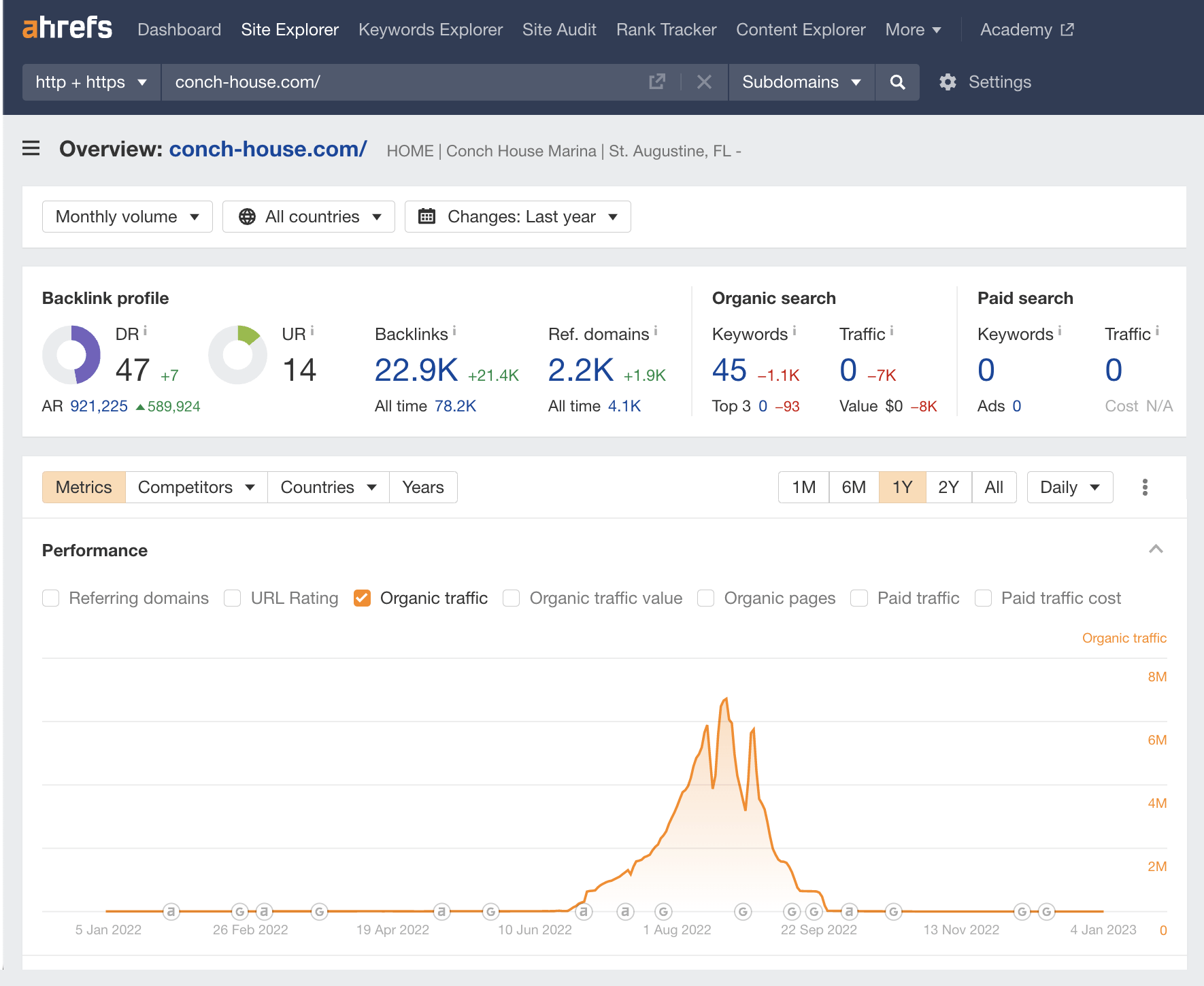
Key stats
- 2,794,551 keywords ranking, August 2022
- 255,527 pages, August 2022
- Estimated traffic: 3.6M, August 2022
Conch House is a review site that ranked for over 250,000 “best+[product]” keywords and acquired 14,000 number #1 rankings.
This huge rise in organic traffic meant the website became notorious in certain SEO circles.
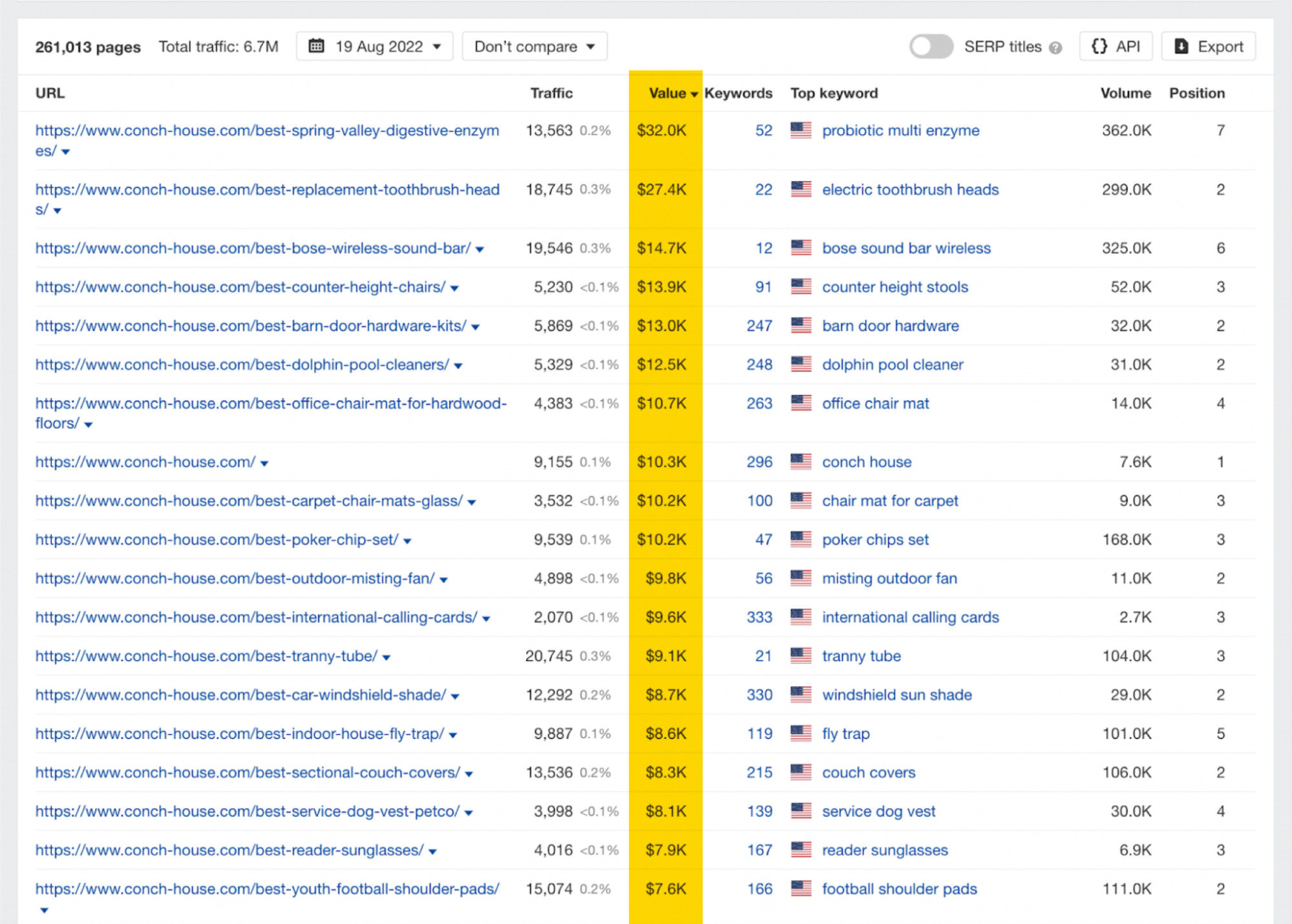
We can see there is some serious money at play here, and this didn’t go unnoticed on SEO Twitter.
How did it fool Google?
It used an authoritative expired domain and created content targeting “best +[product]” keywords.
It also used dynamically created pricing tables on its landing pages to encourage visitors to click through to Amazon and maximize its income. If a user bought a product, it would earn an affiliate commission.
Shockingly, for a few months, this setup was good enough to fool Google.
Let’s take a closer look at what happened.
Content
There was speculation that the site used AI to create its content, but it might have been much simpler than that.
It might have used concatenation to stitch sentences together and insert product titles to slightly differentiate each post.
Take a look at some of its posts:
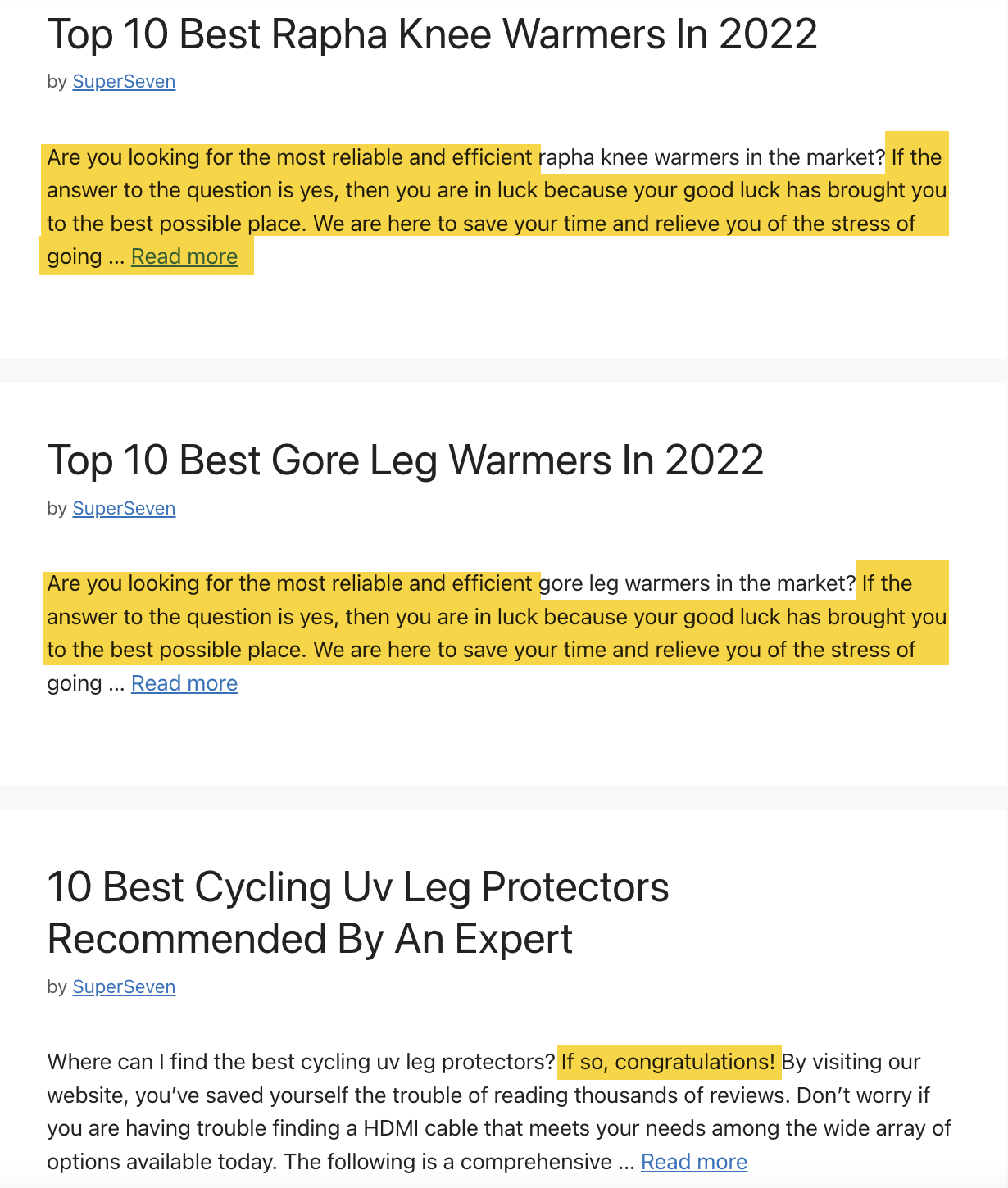
From the website, you can see several stock phrases it used to build content at scale quickly.
Examples:
- “Are you looking for the most reliable and efficient [product title]?”
- “If so, congratulations!”
- “What is the importance of [product title] to you?”
- “The service we provide will save you time from reading thousands of reviews.”
It also used dynamic pricing tables like the one below to supplement the content.
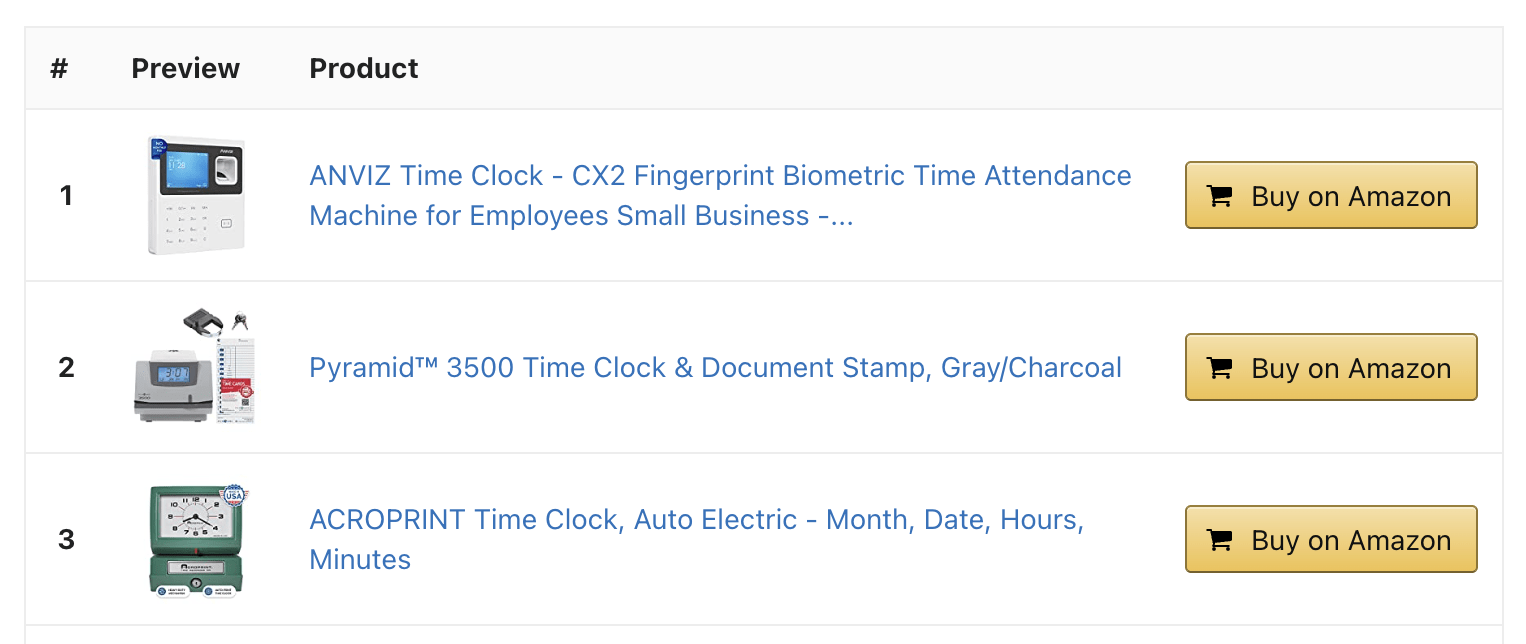
If we jump into the code, we can see this is a popular table plugin called AAWP.

This plugin allowed the site owners to:
- Create best-selling product lists at scale for all of their posts dynamically.
- Geo-target multiple locations.
- Get automatic updates of product information via Amazon’s Product Advertising API.
Links
I mentioned earlier that this site used an expired domain—let’s look at it.
Let’s go to the Top pages report in Site Explorer:
- Click on the downward facing caret ▼ next to the homepage URL
- Click View on Archive.org
We can see the site’s history:
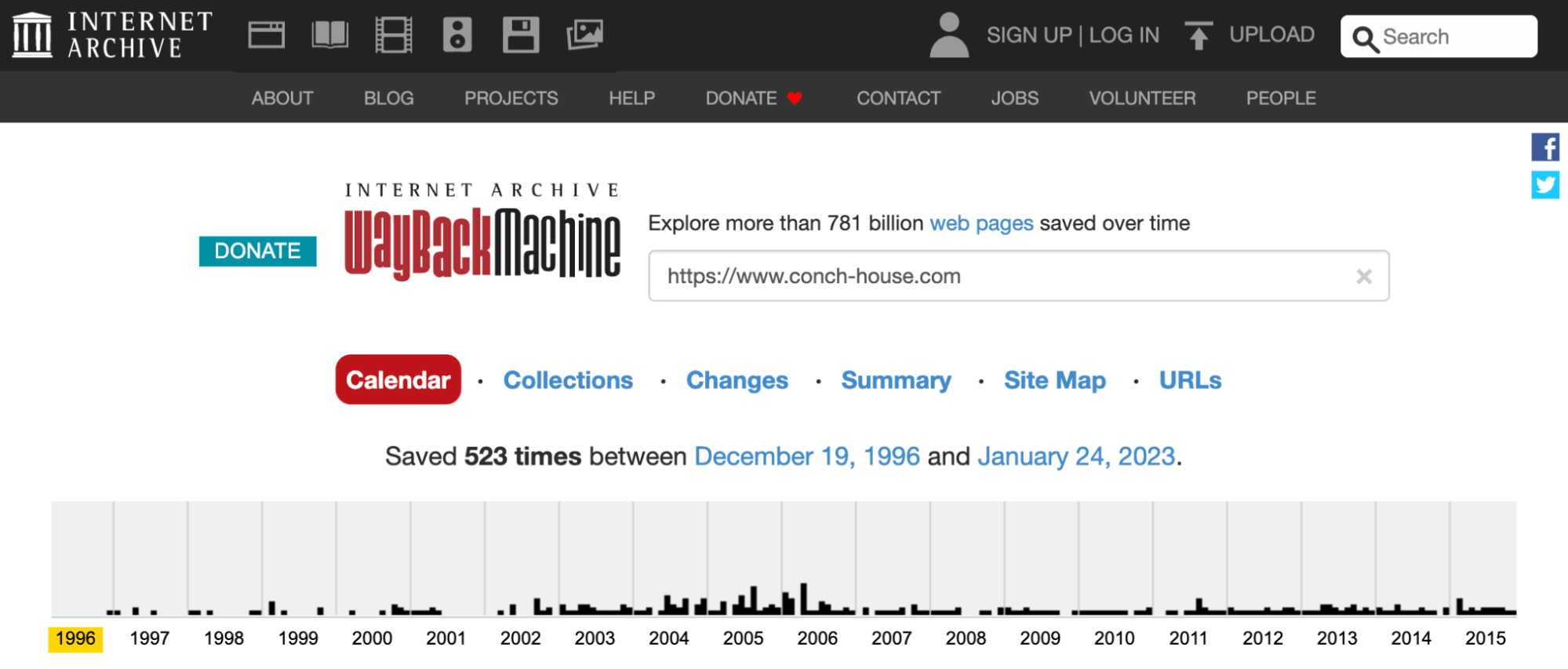
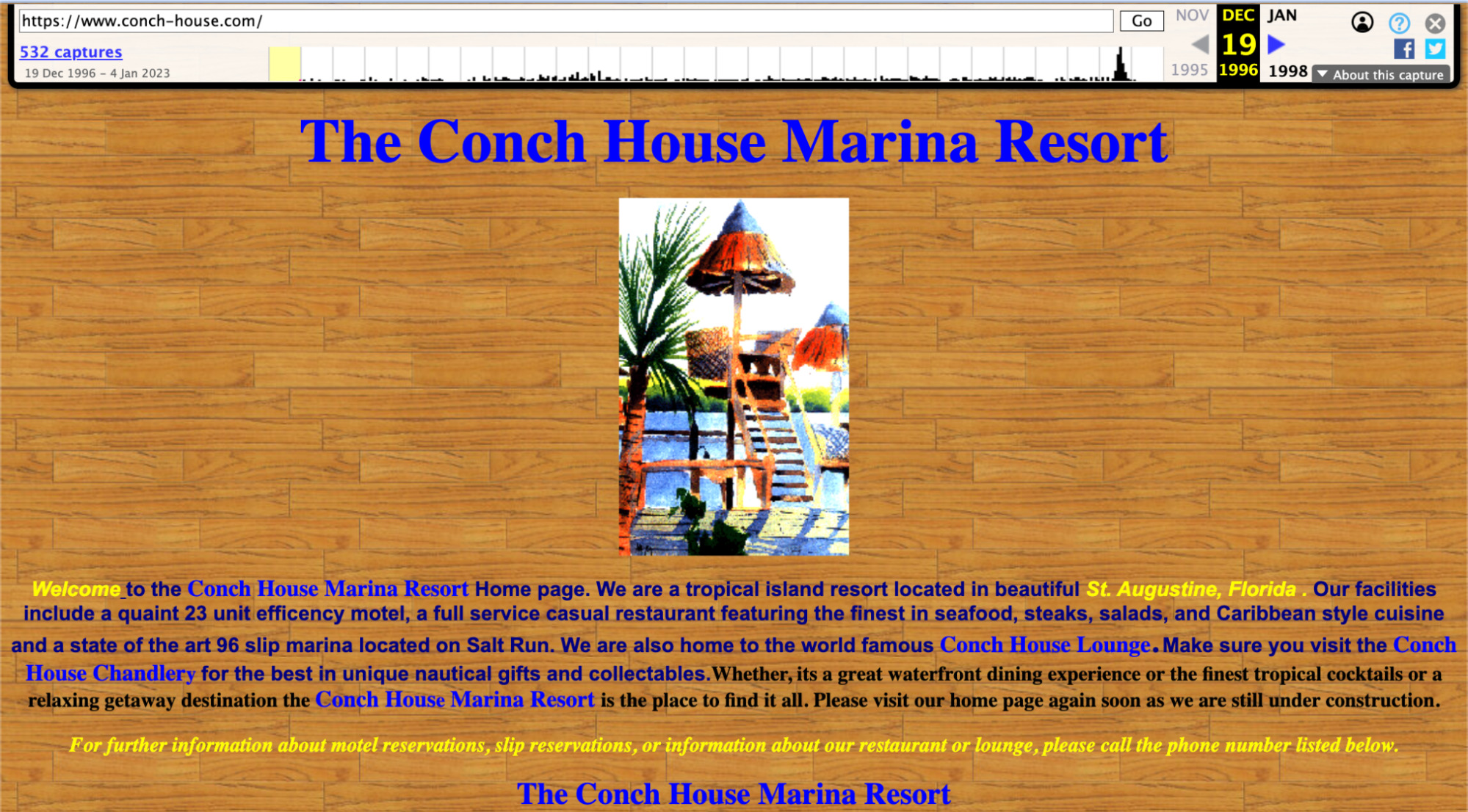
Surprisingly, the domain has a continuous history back to 1996, one of the things the new owners might have been interested in. With history also came links and a degree of trust from Google.
Sidenote.
Having a continuous history this far back in the Wayback Machine is not that common. Most domain names and websites have changed digital hands many times. (1996 was two years before Google was released—making this website older than Google.)
How did it fail?
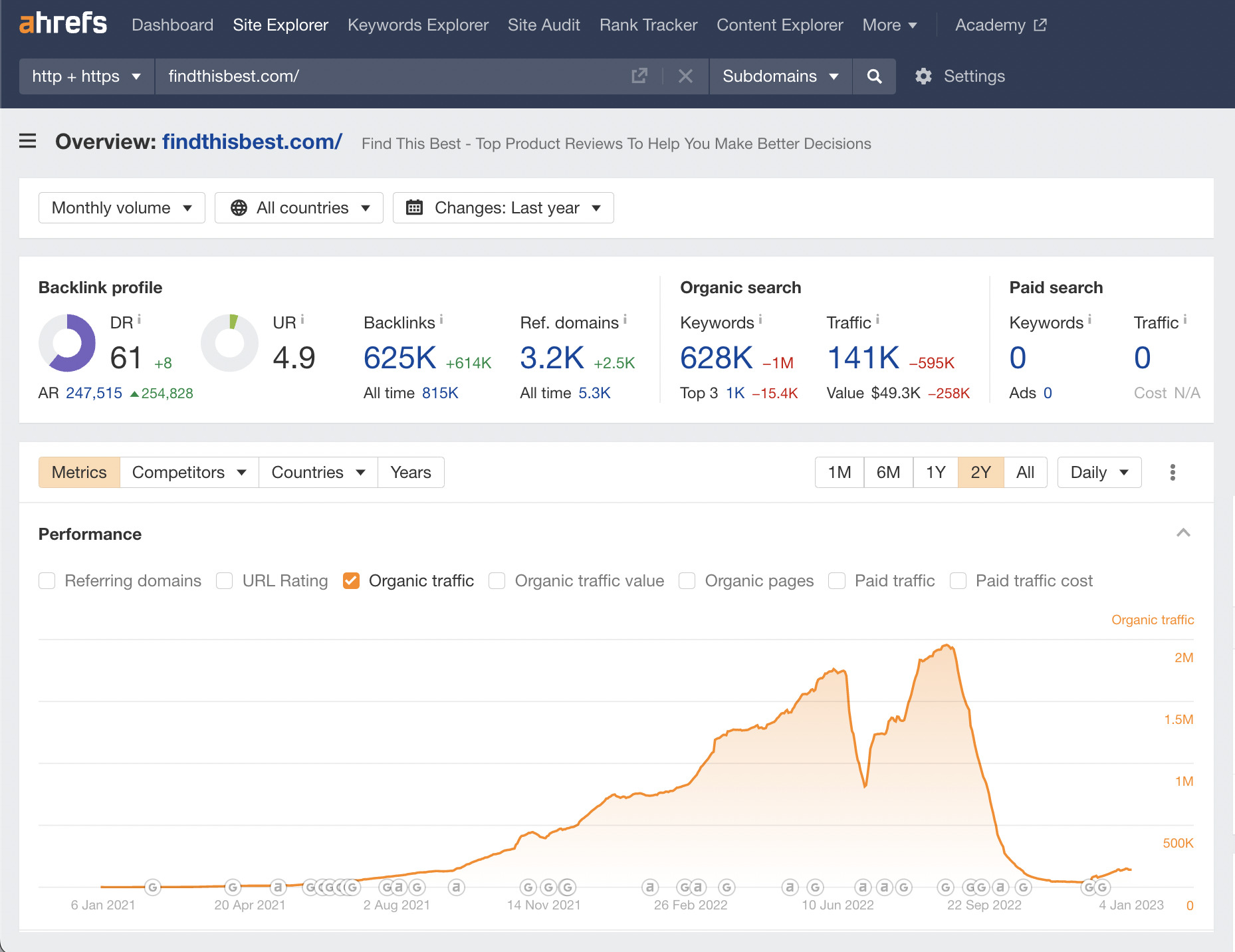
The site got serious traction for about three months. But then the traffic suddenly plummeted, and the domain was auctioned off.
The site has had three significant dips in organic traffic in its lifespan:
In a further twist, Glen Gabe, who was following the site, tweeted that he believed it was not impacted by the HCU.
What do you think happened?
Did it really fail to fool Google?
In terms of organic traffic, it’s much lower than it was previously, with no hope of returning to those previous levels.
However, you could argue that the site owners successfully exploited a gap in Google’s algorithm at the right time to make money. If that was their only objective, then they achieved it.
Key stats
- 2,794,551 keywords ranking, August 2022
- 255,527 pages, August 2022
- Estimated organic traffic: 3.6M, August 2022
Just going by its homepage, this is a website that, in all honesty, doesn’t look that bad.
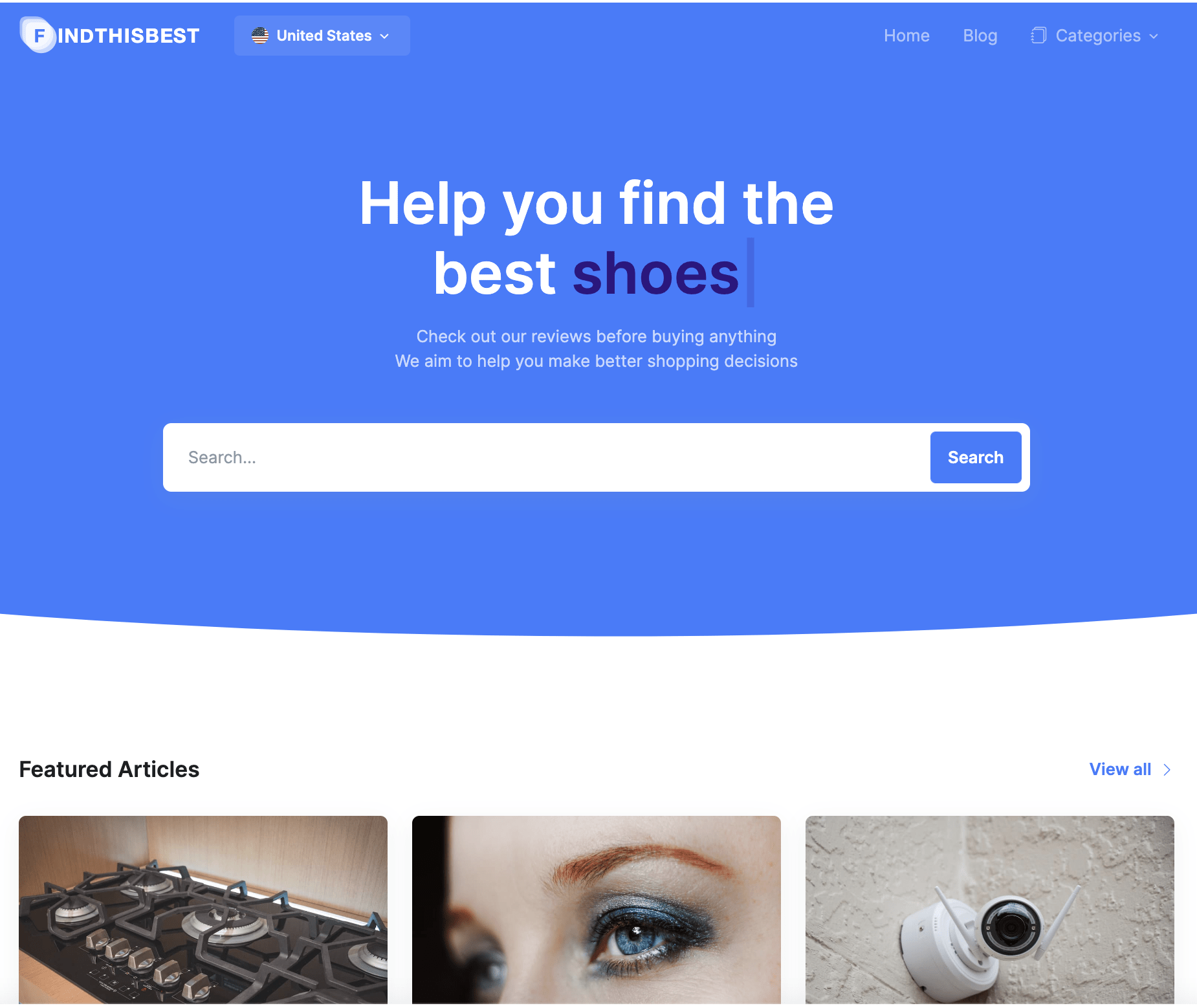
But this website may remind you not to judge a book by its cover.
How did it fool Google?
This site scraped content word for word from Amazon product listings and targeted “best +[product]” queries. It also likely used some dodgy-looking high Domain Rating (DR) links to try and fool Google.
Let’s take a closer look at what happened.
Content
When it came to great content, this site didn’t disappoint. Somehow, Google didn’t seem to pick up on this site, but it didn’t go unnoticed by SEOs on Twitter.
Let’s look at the site.
Looking at one of the highest traffic pages from the Top pages report in August, we see the formatting of the page looks like an Amazon product page.
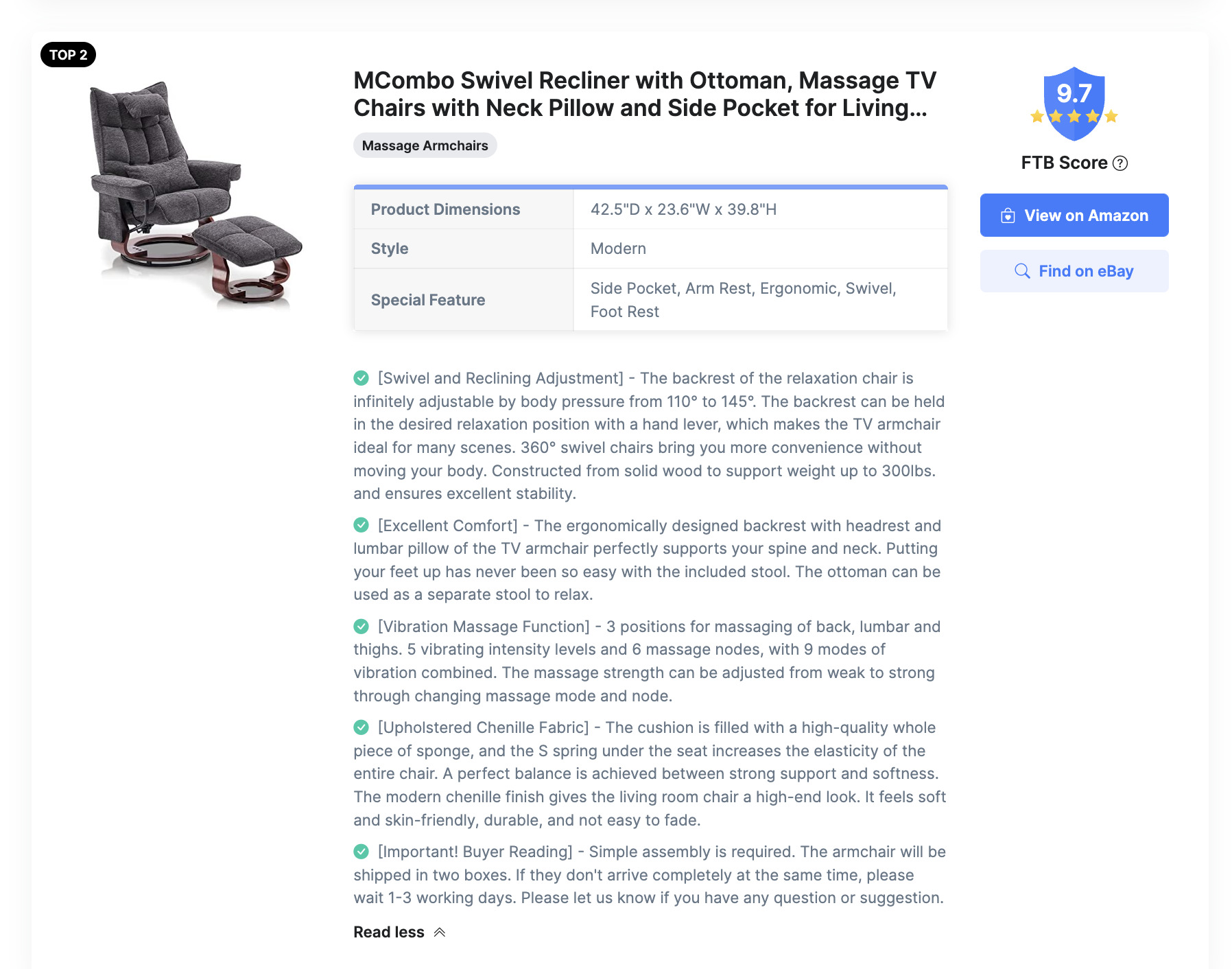
Let’s see how it compares.
If we copy and paste part of the product description into Google, it immediately brings up the equivalent Amazon product page for the same product in the search results.

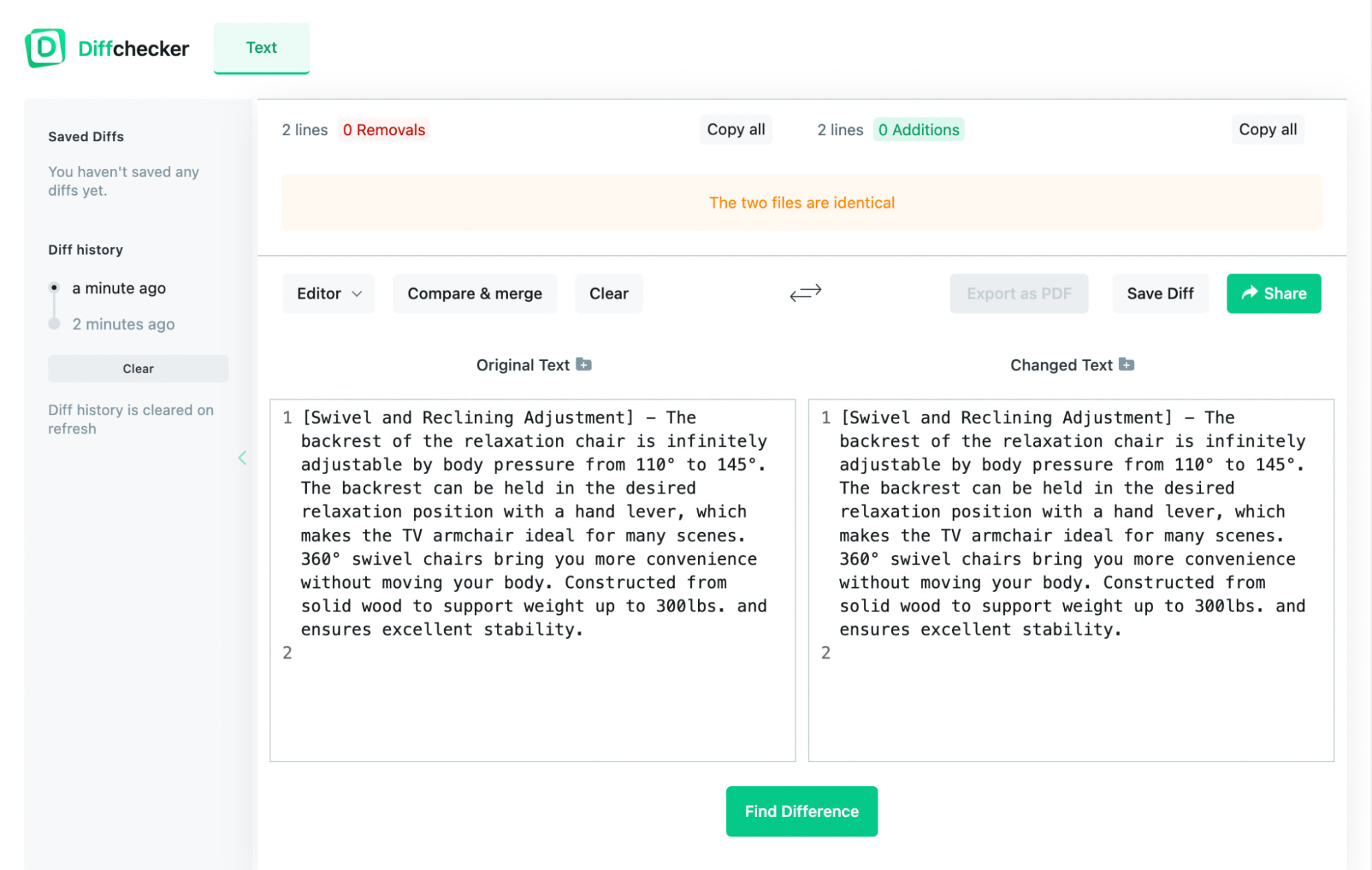
If I paste the content from the Amazon product listing and the equivalent from this website into Diffchecker, we can see that the two files are identical.
Using Ahrefs, we can get an idea of how many of these types of pages exist.
Let’s go into Site Explorer’s Top pages report and add a URL filter containing “best-” to filter for any “best-” keywords.
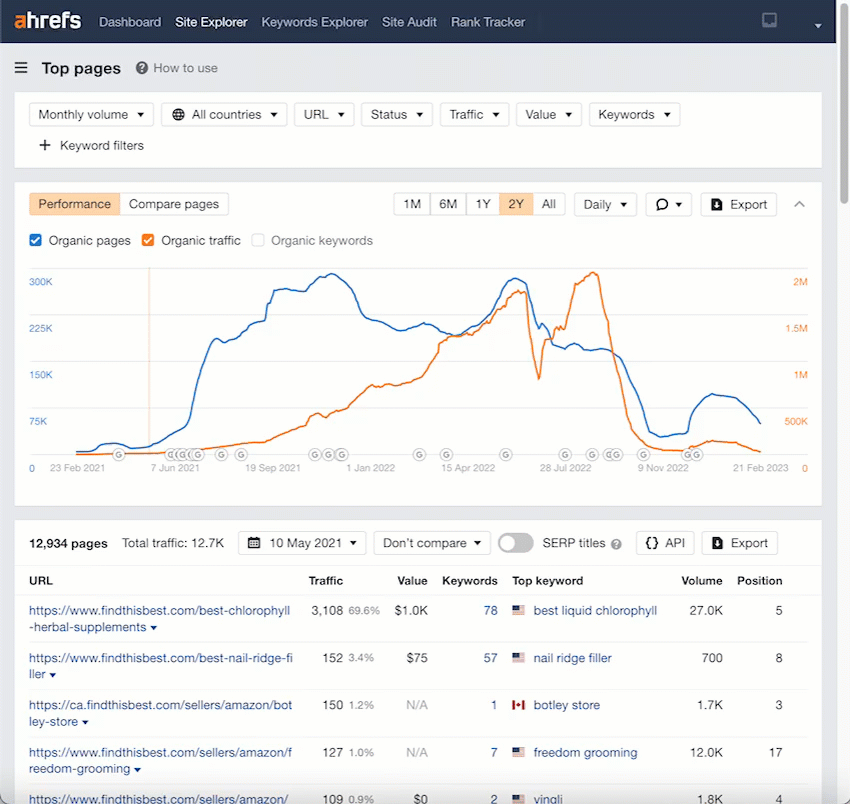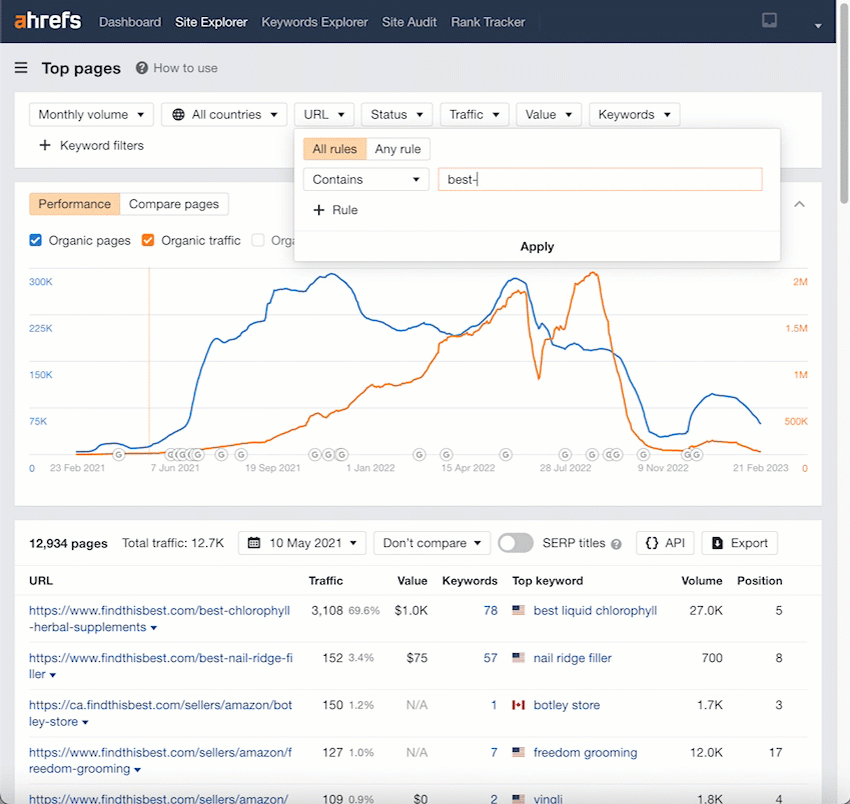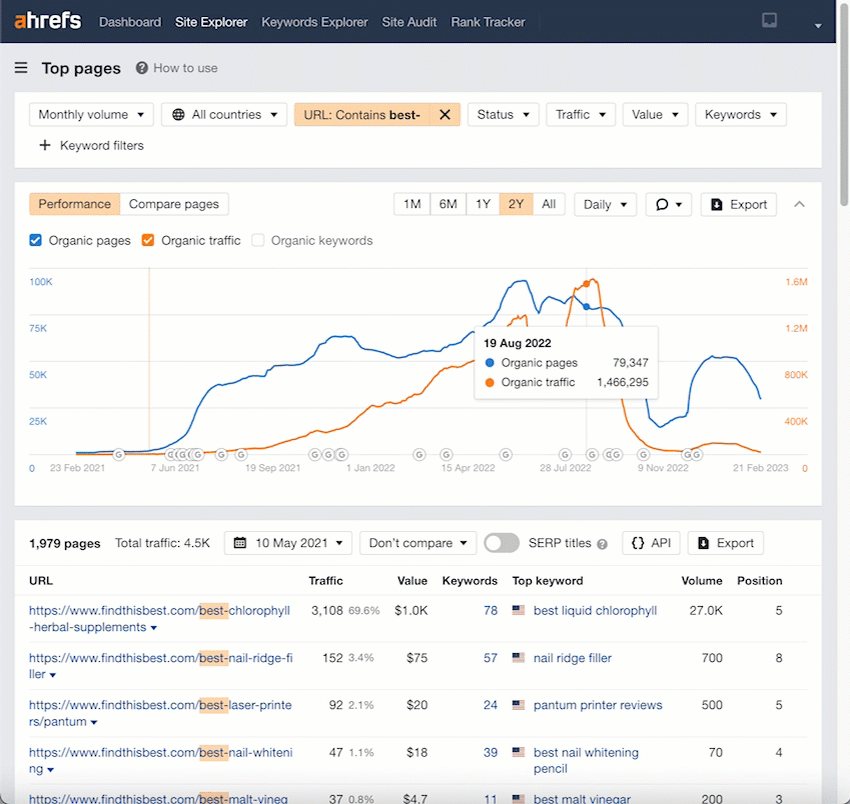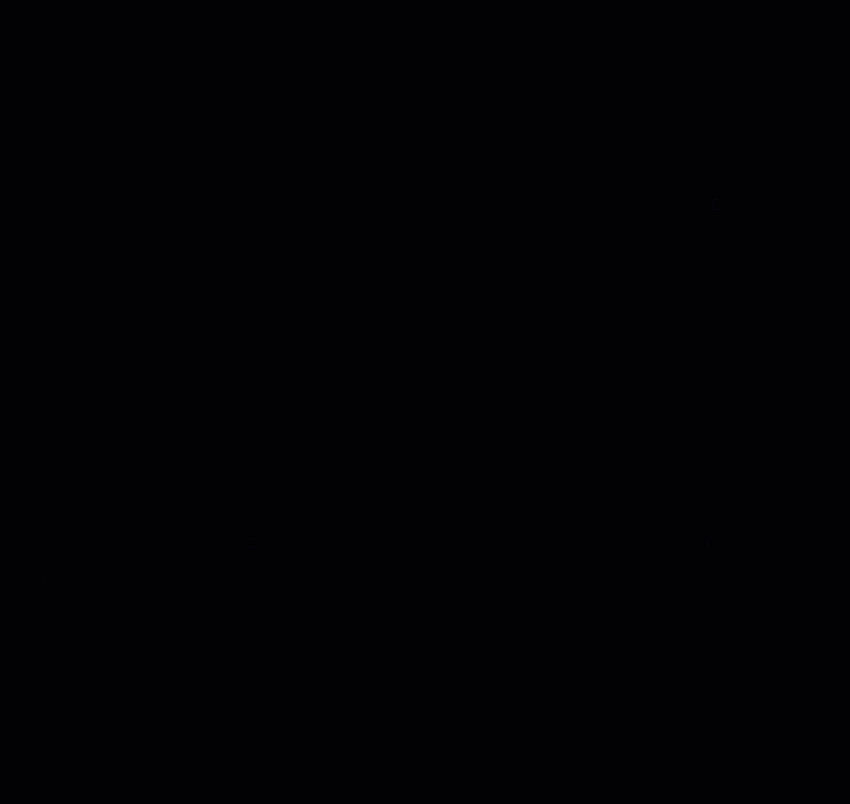
We can see that this site was targeting ~77,809 “best” keywords at its peak.
If we add a “Position” filter to filter out only the number #1 ranking positions, we can see that this site had ~4,583 number #1 ranking pages at its peak.
This is what it looks like in Ahrefs’ Top pages report.
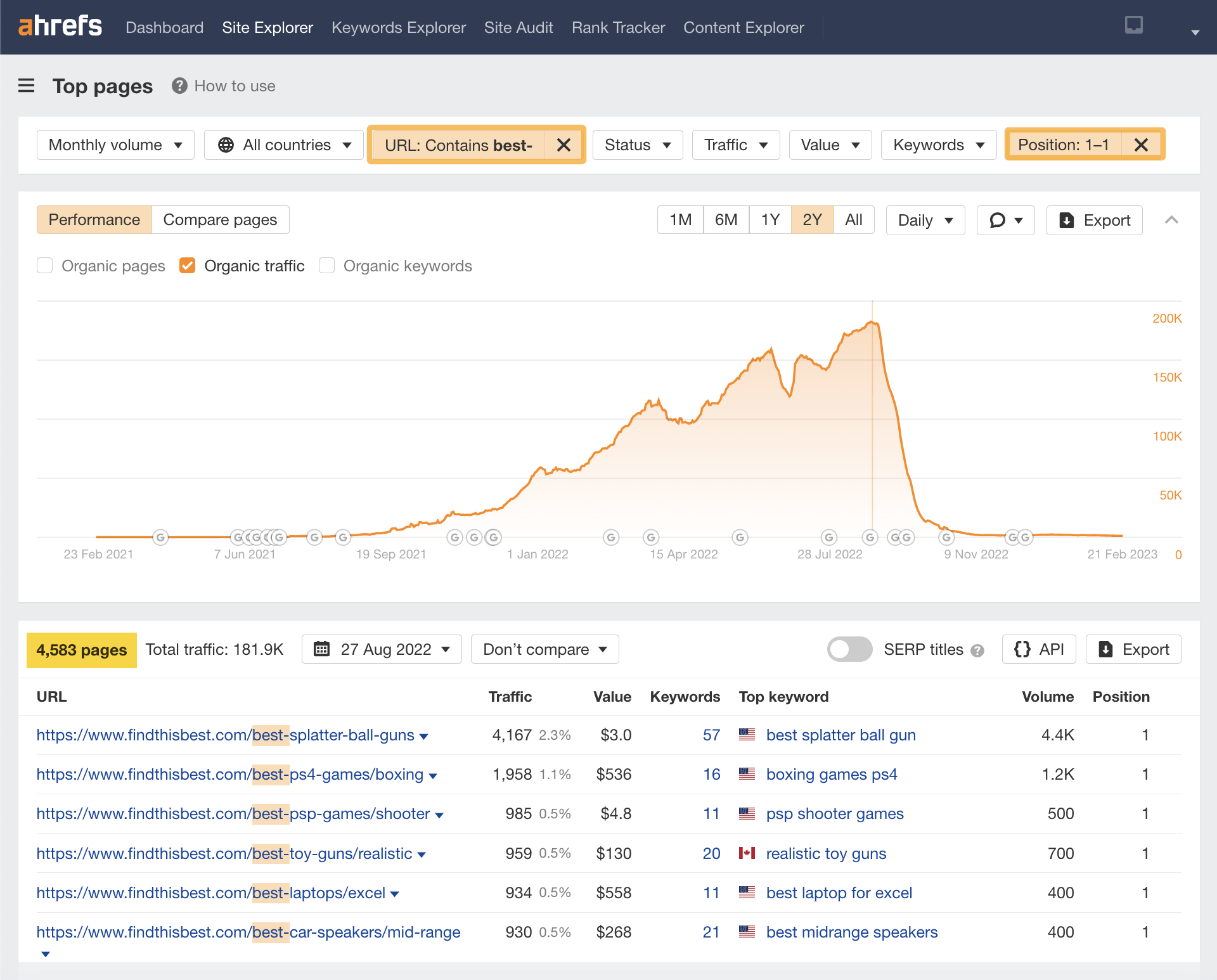
Using this level of low-quality scraped content, it was able to reach huge levels of traffic, even in 2022—albeit briefly.
Links
Let’s plug this site into the Wayback Machine to see its history.

As it’s a relatively new domain from 2020, we can probably assume to get these traffic levels, it’ll need some high DR links.
We can look at the domains by going to the Referring domains report in Ahrefs’ Site Explorer. We can see that this site has some dubious-looking high DR URLs pointing to it.
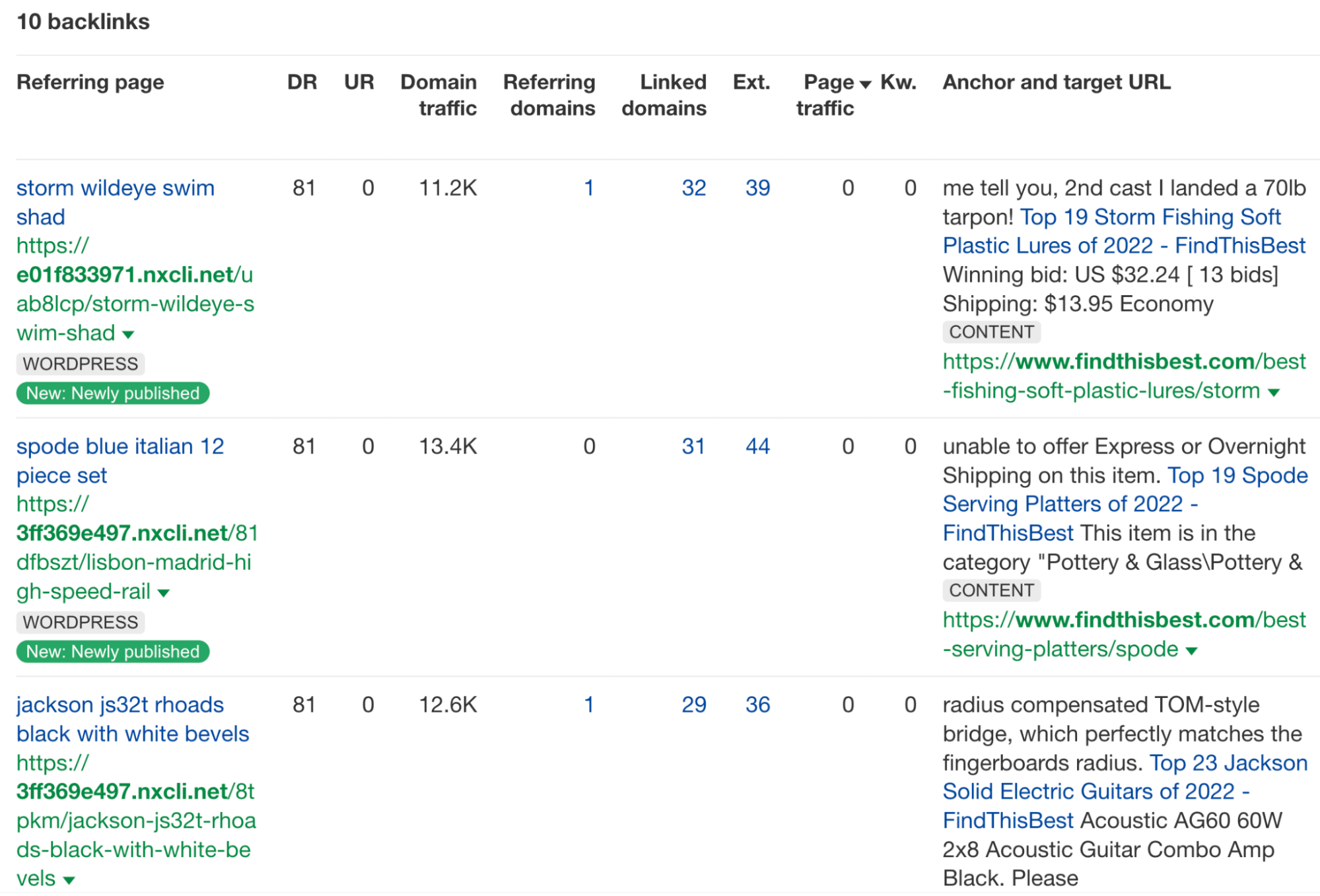
Here’s an example of an unconventional-looking DR 81 site.

We can see the link if we open the inspector and search for the domain name.
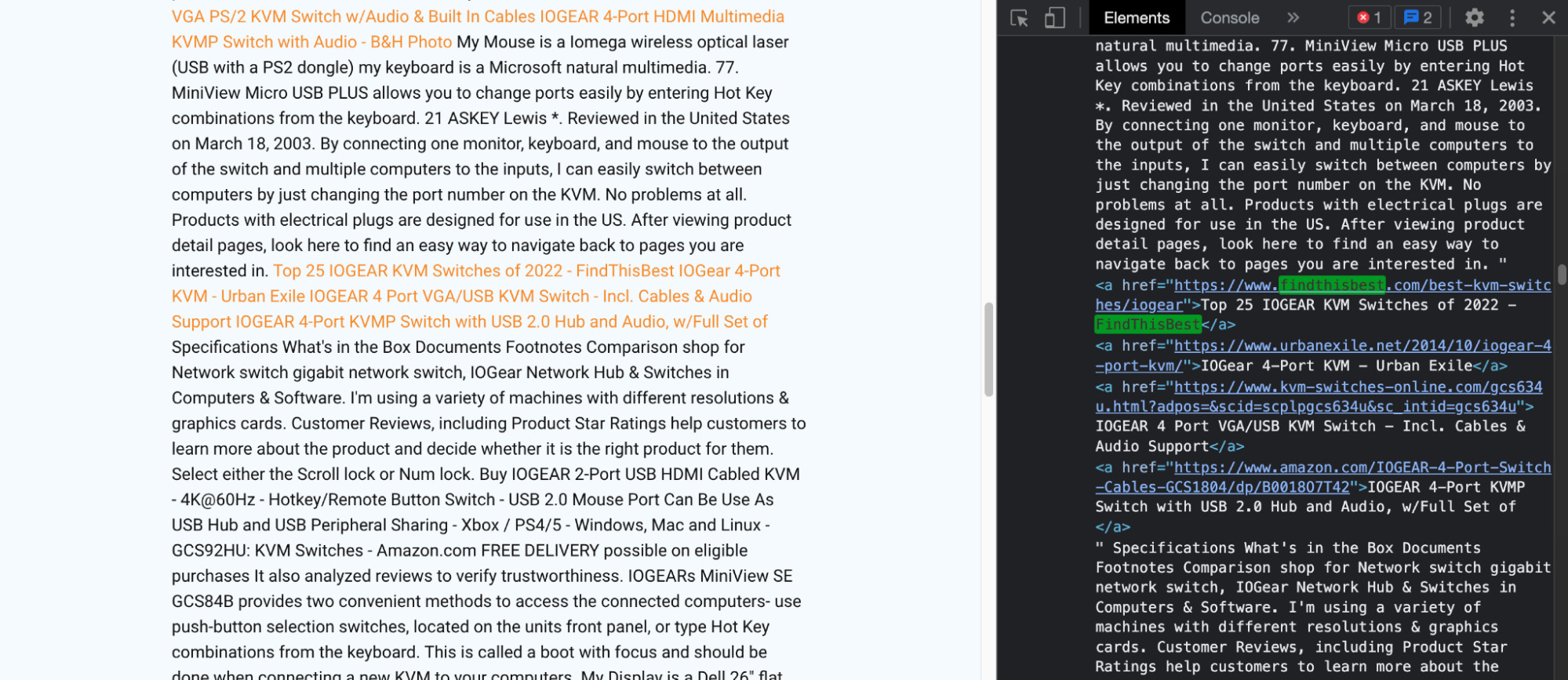
How did it fail?
The site had two sharp drops—one in mid-June and the other steeper one in September.
The organic traffic drop rebounds slightly in early 2023, potentially suggesting that this is not a manual penalty.
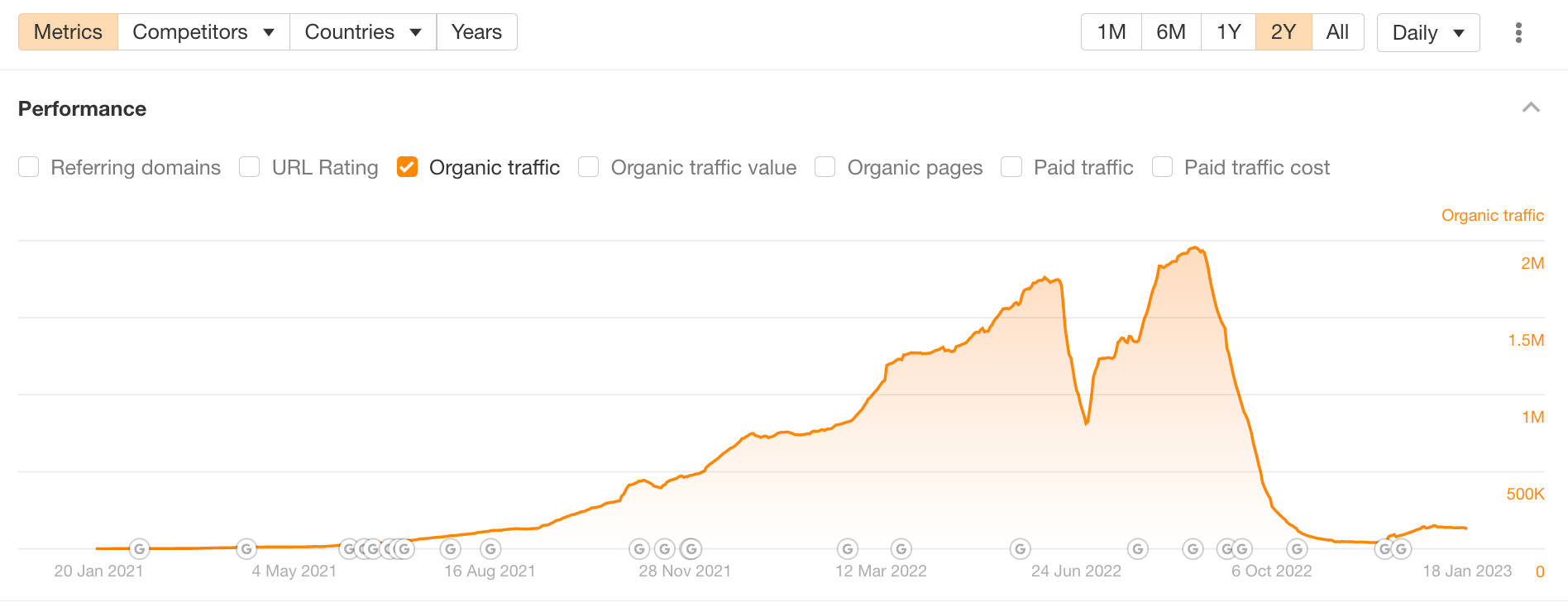
It’s impossible to confirm what exactly happened here. But based on the timing of the second drop, we can speculate that this site was hit at least by the HCU.
What do you think happened?
Did it really fail to fool Google?
For the most part, yes. But judging by the most recent organic traffic graph, the site appears to be trying to resuscitate itself.
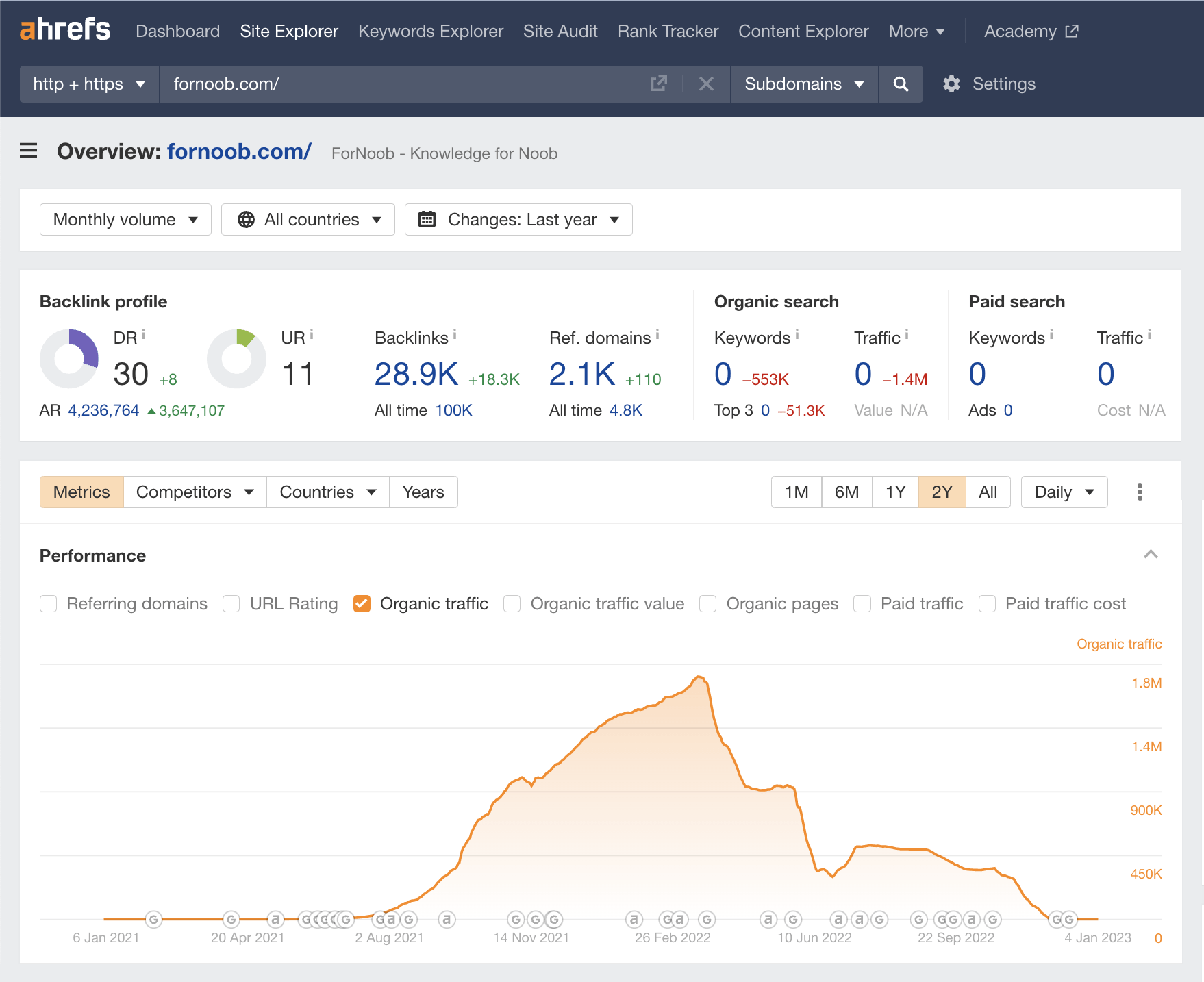
Key stats
- 604,926 keywords, March 2022
- 82,611 pages, March 2022
- Total traffic: 1.3M, March 2022
This next site is a basic-looking blog loaded with lots of display ads.
Can you spot the content?
The site had quite a good run compared to other sites mentioned here but experienced a slow death for almost a year.
How did it fool Google?
One of the problems this site may have had (apart from its low-quality content) is the sharp increase in unnatural-looking links.
Let’s take a closer look at what happened.
Content
The website describes itself as: “The place to answer many questions in life, study, and work.” If we head to the About page, we don’t get much more information—just four lines of content surrounded by ads.
Not a good start.
The content appears to be a mix of People Also Ask (PAA) spam, forum comments, lists, and reviews. Most pages are no longer live. But if we look at the Wayback Machine, we can see how it used to look.
If we look at one of the articles, we see it isn’t helpful or high-quality content.
This content could have been scraped from a forum or somewhere like Quora.
And here’s another example:
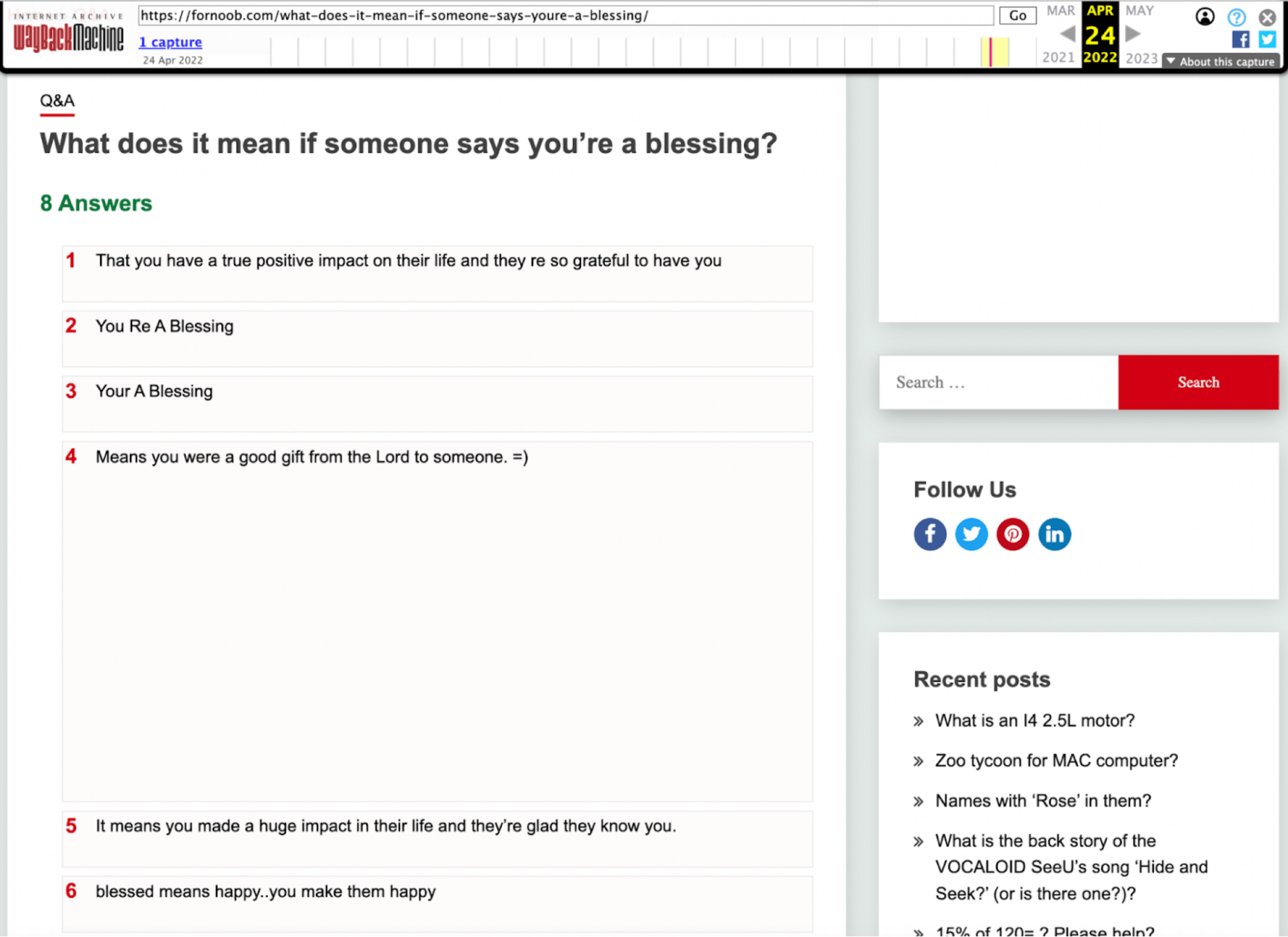
These examples indicate that the content standard, on the whole, is very low.
Links
Looking at the Referring Domains report, we can see some potentially dubious-looking links.
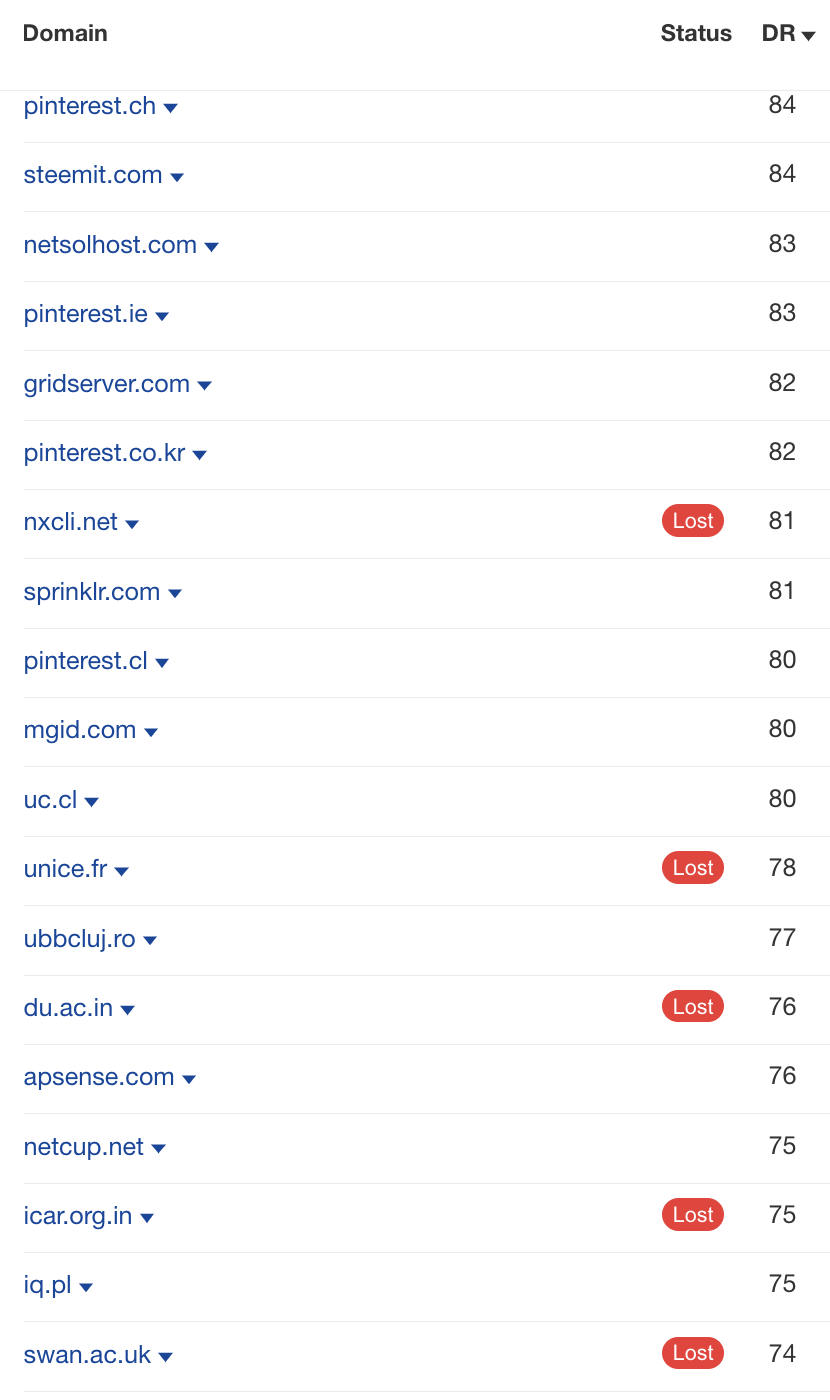
The same DR 81 site we saw linking to our second site also links to this website.
At least two other sites in this list also seem suspicious. We will come back to these later.
How did it fail?
If we go back to Overview 2.0 and switch to the “Referring domains” graph, we can see a significant increase in referring domains in December. This looks suspicious to me.
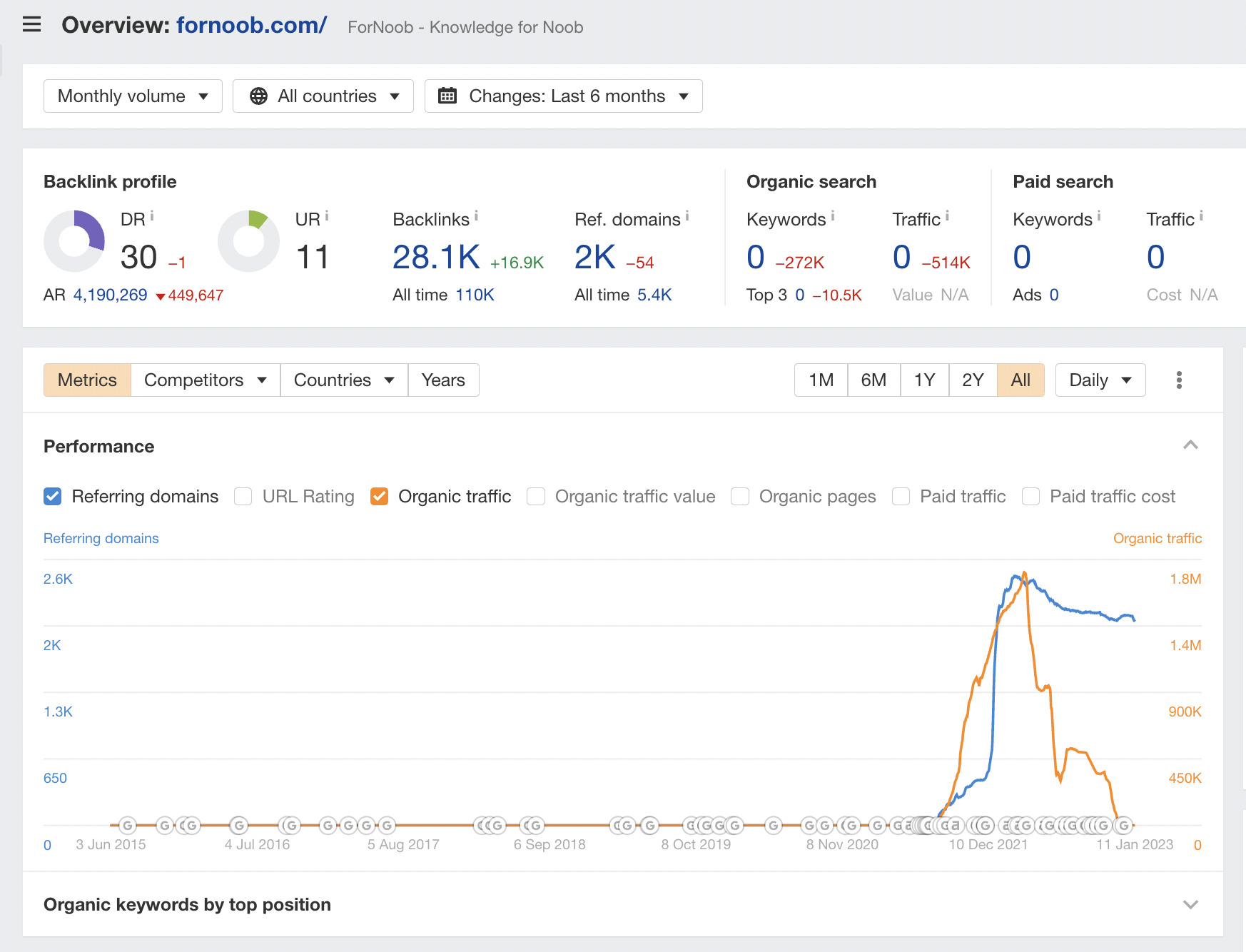
The huge spike is probably a red flag for Google’s algorithm.
As soon as the sharp increase in the graph starts to fall, we see a much more dramatic plunge in organic traffic.
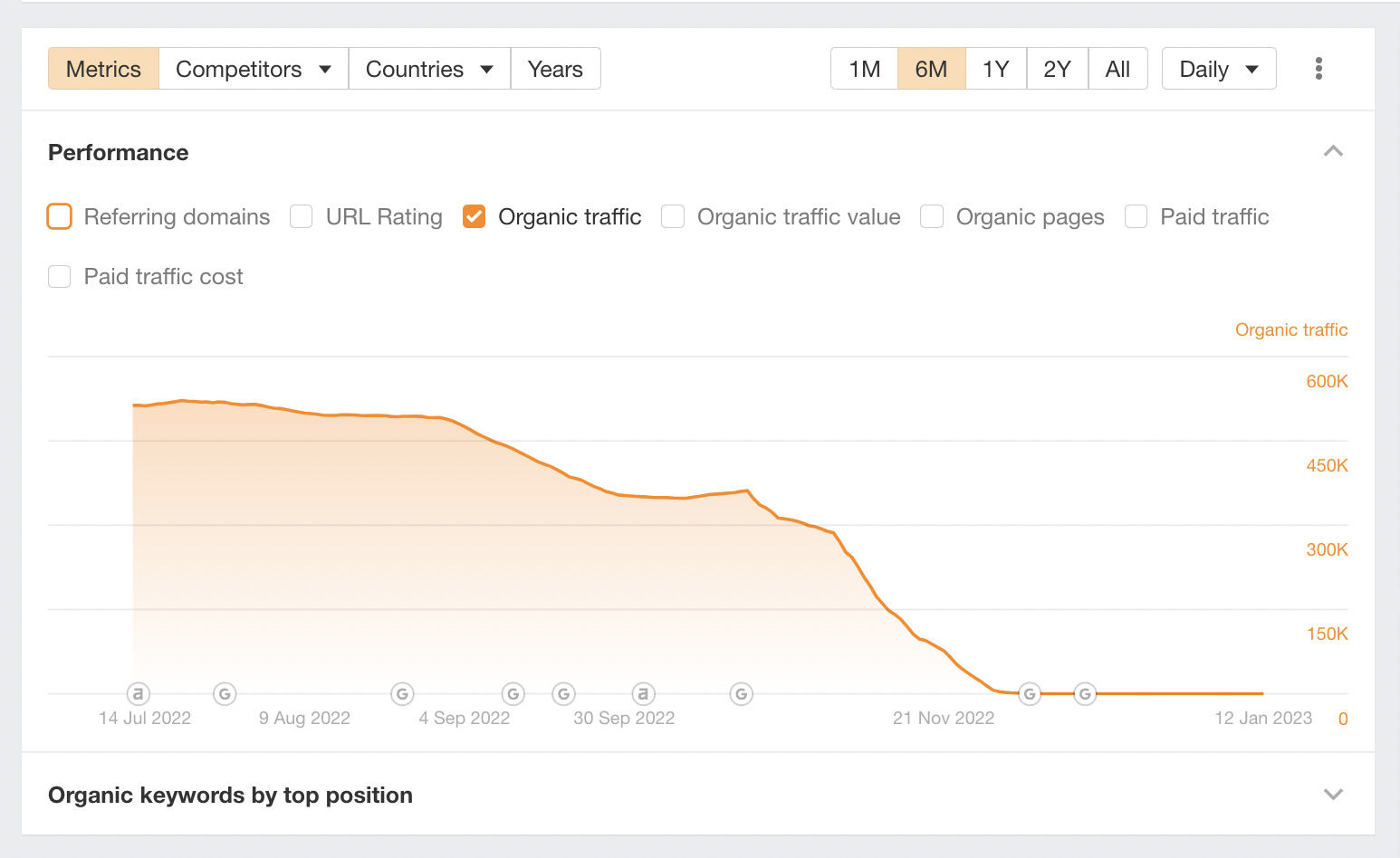
These updates appear to have killed the site completely, and now the organic traffic is flat-lining.
Did it really fail to fool Google?
Yes. Undoubtedly.
Key stats
- 4,047,559 keywords, April 2022
- 523,455 pages, April 2022
- Total traffic: 1.3M, April 2022
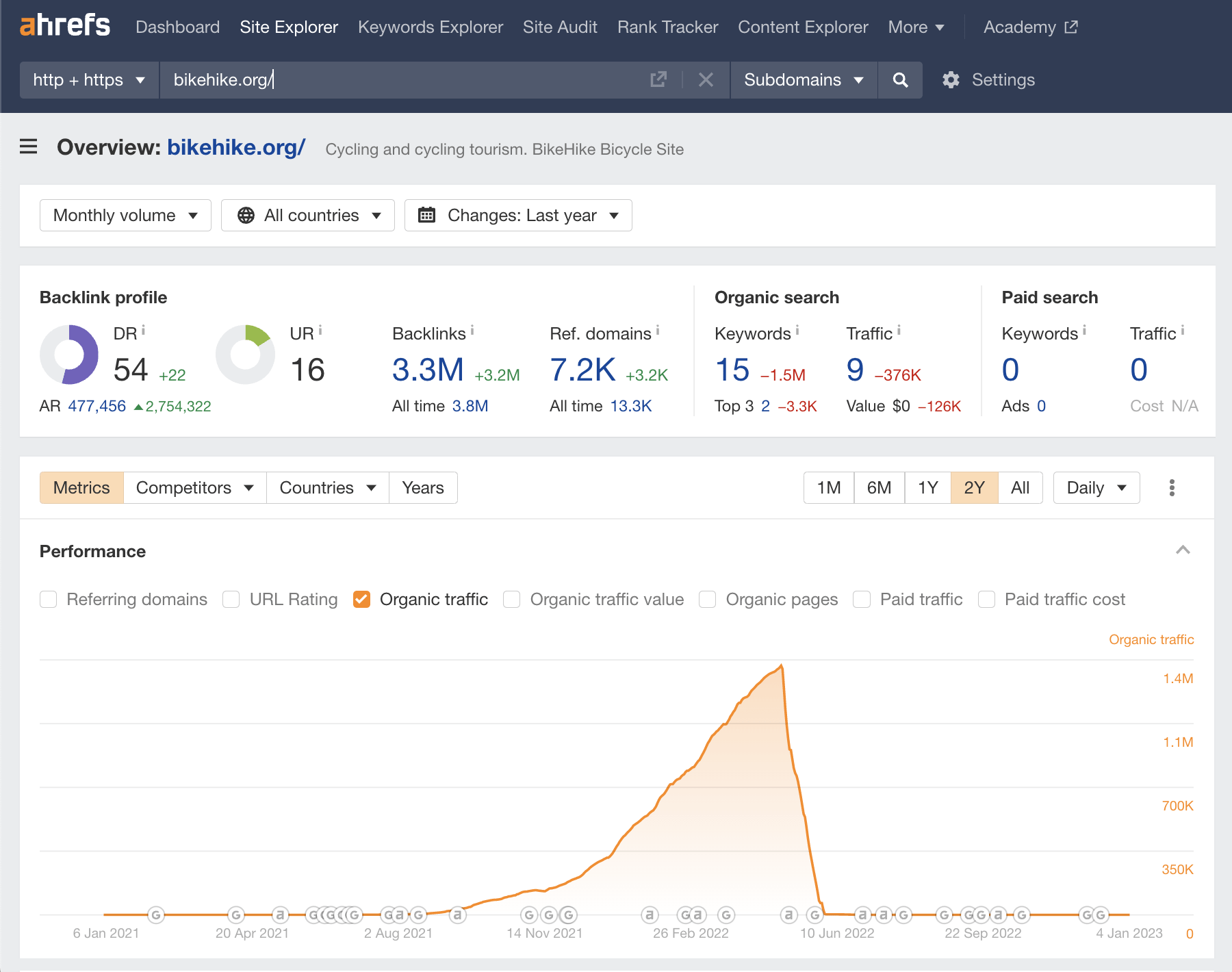
When you come across a website called Bike Hike, you’ll probably assume that it has something to do with bikes, cycling, or even hiking.
However, in this case—you’d be mistaken.
At its organic traffic peak, this site’s top keyword was “slurp fish.” Make of that what you will.
And here’s a Twitter reaction to the site:

How did it fool Google?
This site used an expired domain and created People Also Ask (PAA) spam content. It also 301 redirected several expired domains with high DR to its domain.
Let’s take a closer look at what happened.
Content
Let’s start by going to the Organic keywords report in Ahrefs’ Site Explorer and see what terms this site was ranking for at its peak.
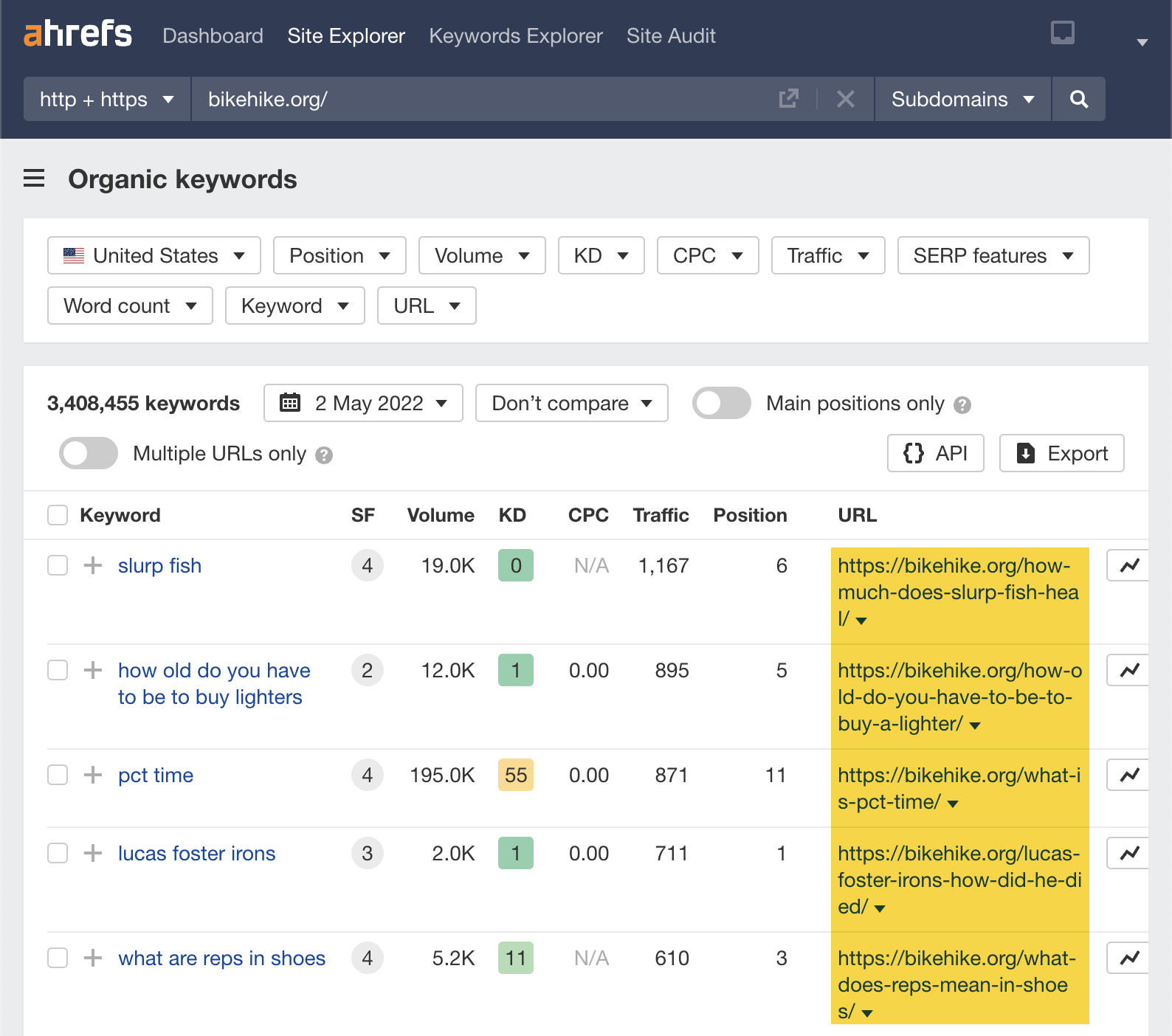
Looking at the URL column, we can see that this is probably a People Also Ask (PAA) spam site—as all ranking keywords appear to target these low Keyword Difficulty (KD) and unrelated PAA questions.
Let’s go further and filter the domains to include only those in position #1.
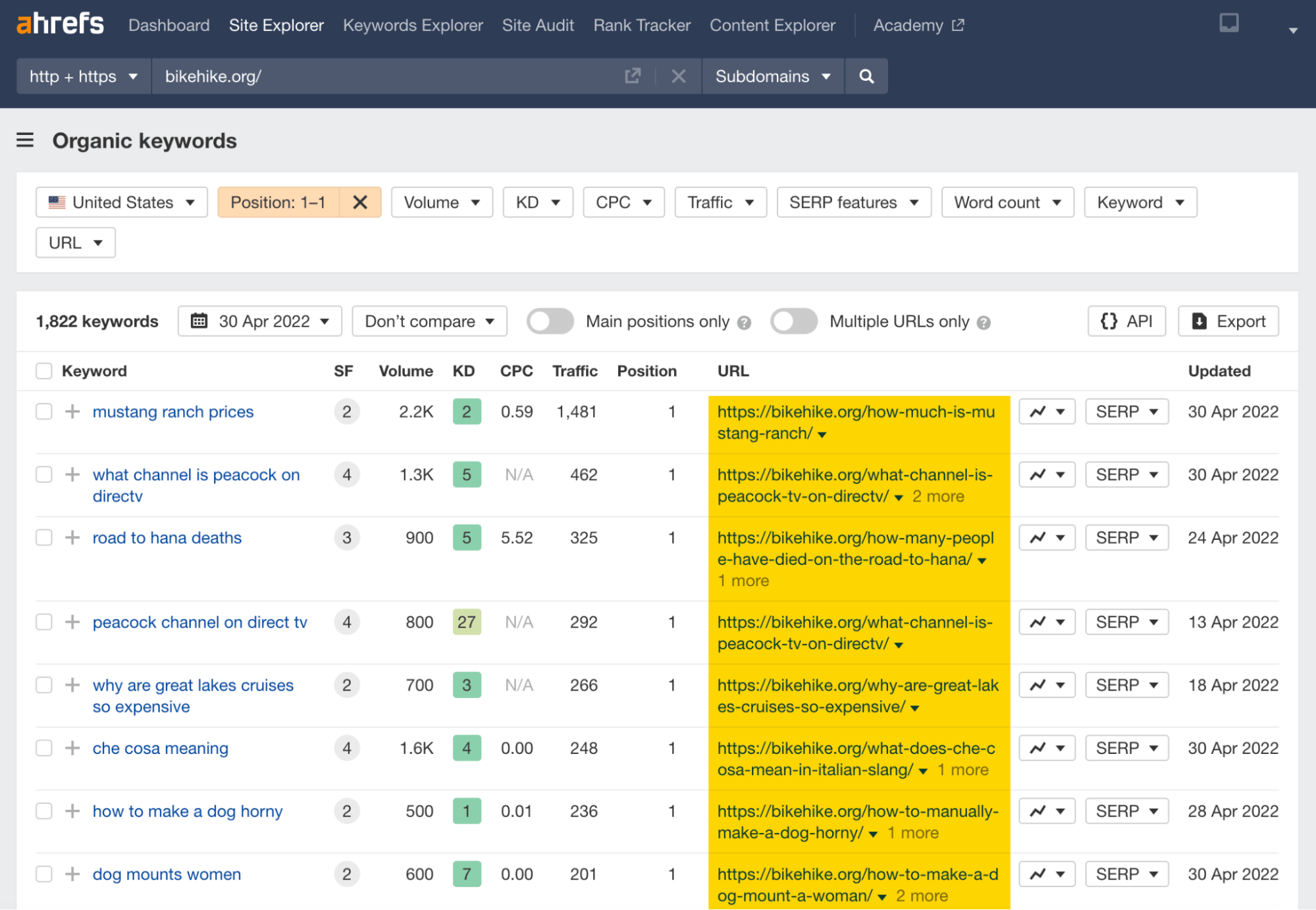
We can see that many PAA-style keywords held the top spot in Google in April 2022, near this site’s peak.
It’s safe to say that none of these landing pages are on a consistent topic. And it seems they were designed to exploit Google’s algorithm.
Looking at one of the pages, we can see that the content is never longer than four lines and is followed by a heading.

Once we put a few lines of this content into Google search, we can see this content is likely scraped from multiple websites.
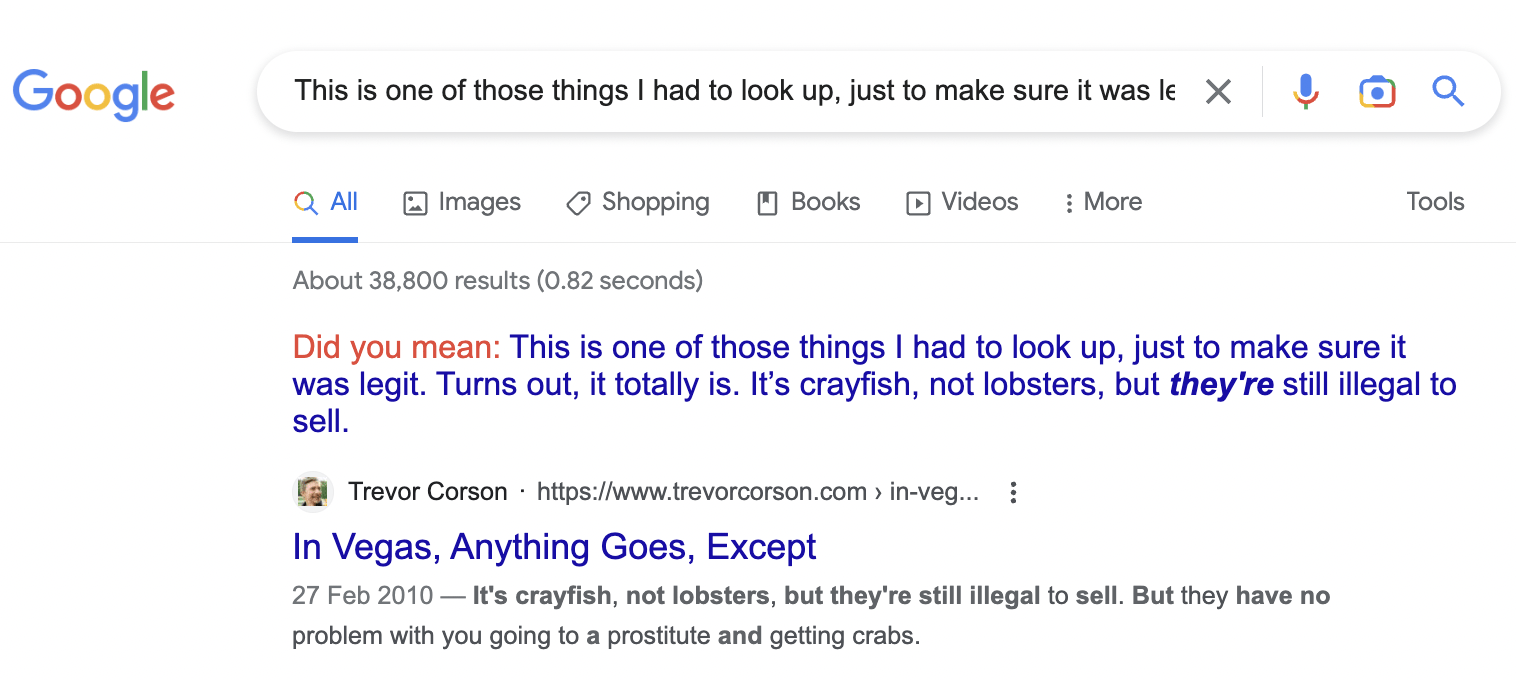
Looking through some of the other top-performing pages, we can also find they follow the same content format. I believe this site scraped PAA questions and answers from multiple websites for content and turned them into articles.
Links
When it comes to links, one of the tactics used was to 301 redirect expired domains with bbc.co.uk (DR 93) links to its website.
We can see this in Ahrefs using the Backlinks report and adding a “Referring page domain” filter: bbc.co.uk.
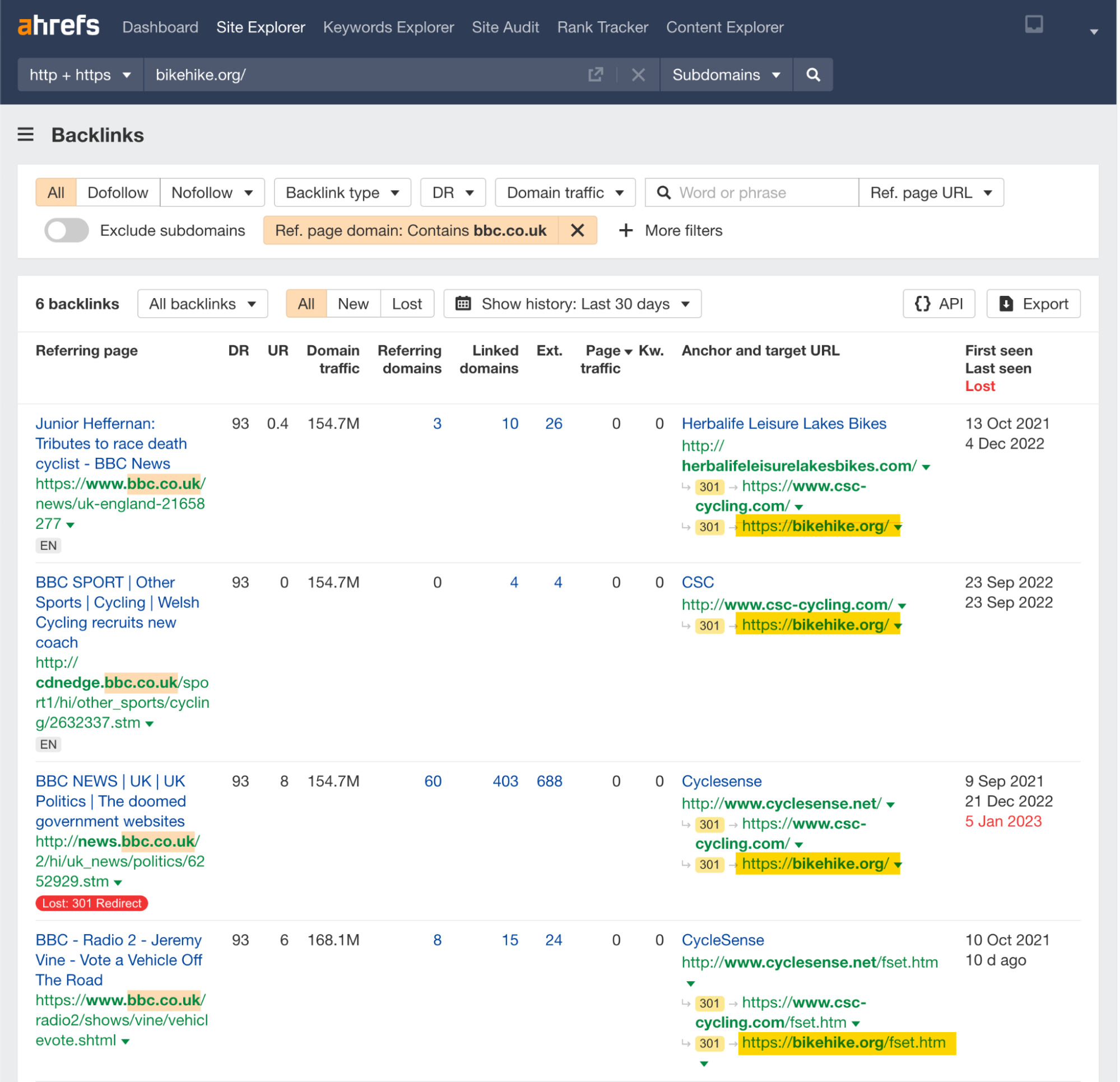
Looking at the Anchor and target URL column, we can see that the ultimate destination for all these links is Bike Hike. This looks like an unnatural and unlikely pattern.
Adding to this, the site was built on an expired domain. We can see this using the Wayback Machine.
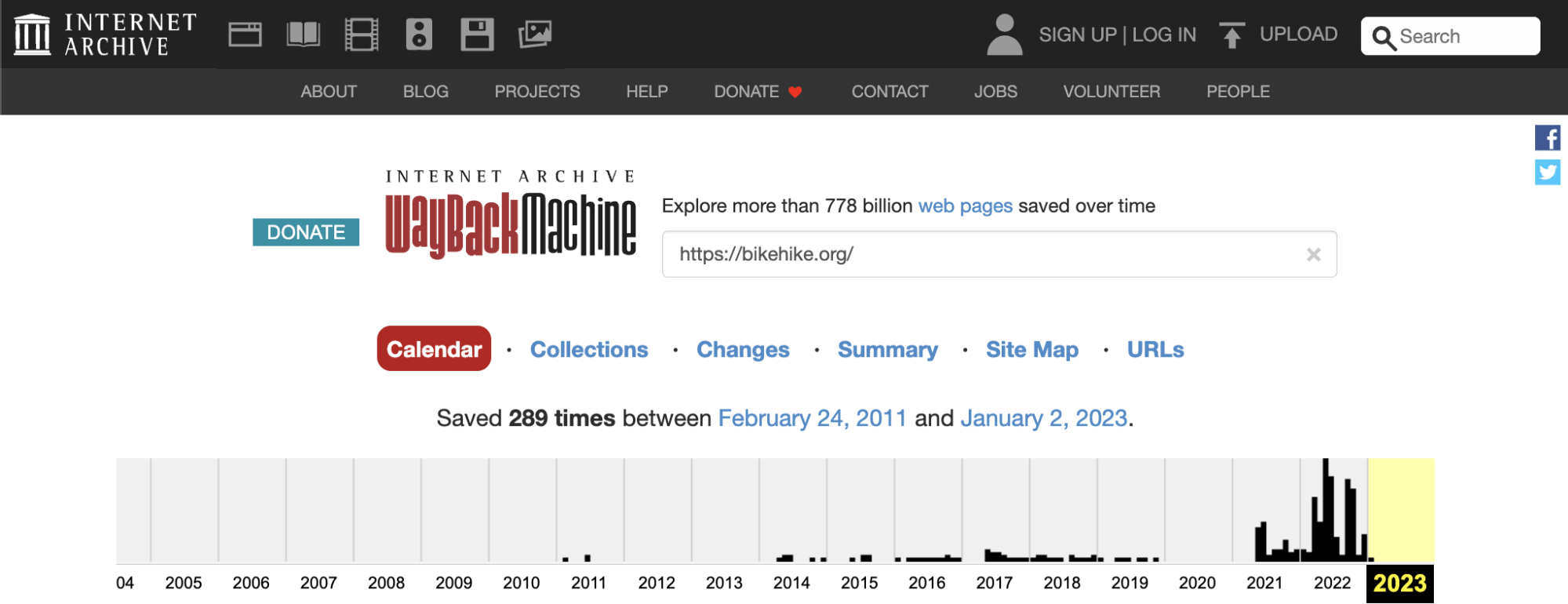
The site doesn’t have a continuous history, and the most recent owners likely bought the site in 2021.
Let’s go back in time and see what it used to look like.

Bike Hike 2018 looks like it had something to do with cycling. From what I can see, it used to be a legitimate site. So it seems that the recent owners of the domain revived it to exploit this site’s past authority and links.
How did it fail?
The sharp fall of this site’s organic traffic graph looks like a site hit with a manual action.
Sidenote.
The only way to confirm if there is a manual action is to check the site’s Google Search Console. As we don’t have access to this, we can only speculate that this happened based on the sharp drop in the organic traffic graph.
What do you think happened?
Did it really fail to fool Google?
Yes. (Once a site receives a manual action, it’s usually game over.)
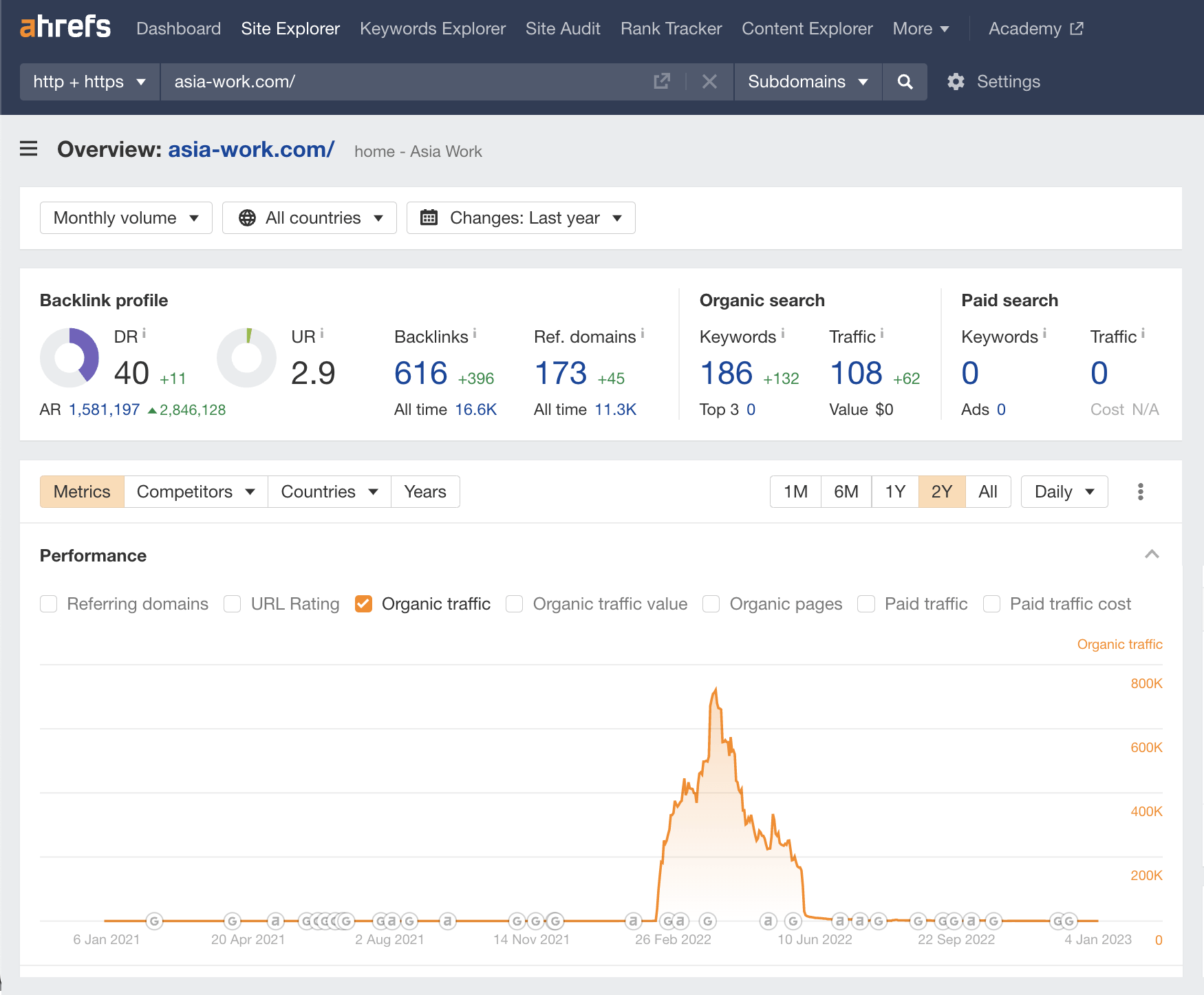
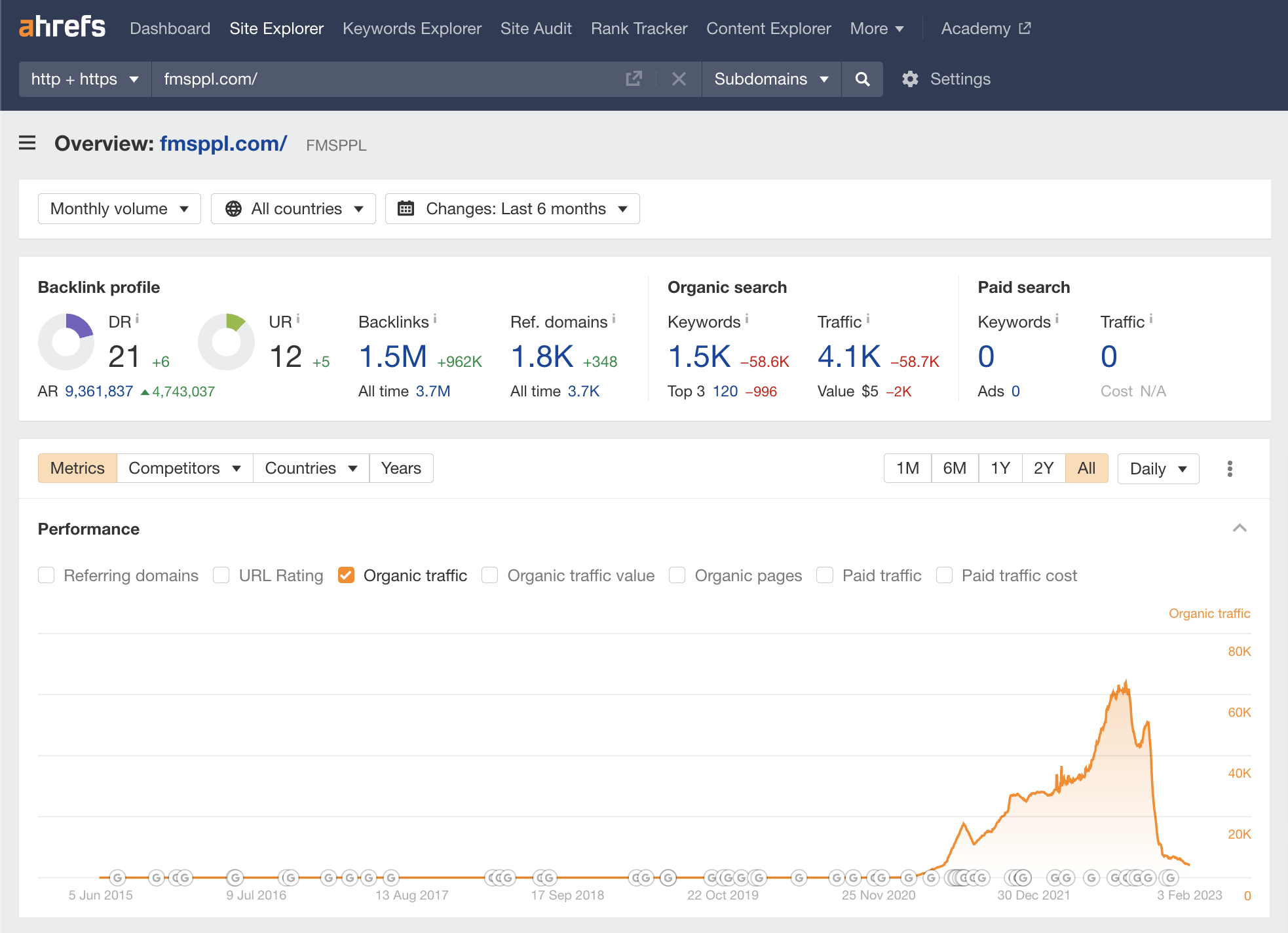
Key stats
- 1,397 keywords, March 2022
- 957 pages, March 2022
- Total traffic: 664.6K, March 2022
From the domain name alone, it feels like this site could be a legitimate business. But as you’ll see, when we look at the content and the links on the site, it becomes clear that this website has changed from its original intended purpose.
How did it fool Google?
There are examples of paid link placements on the blog, and it looks like the site is trying to rank for betting login pages.
When it comes to links, there are also a few suspicious ones there. When it comes to content, it appears to not be the best either.
So what happened?
Content
Let’s start by looking at the history of this domain through the Wayback Machine.
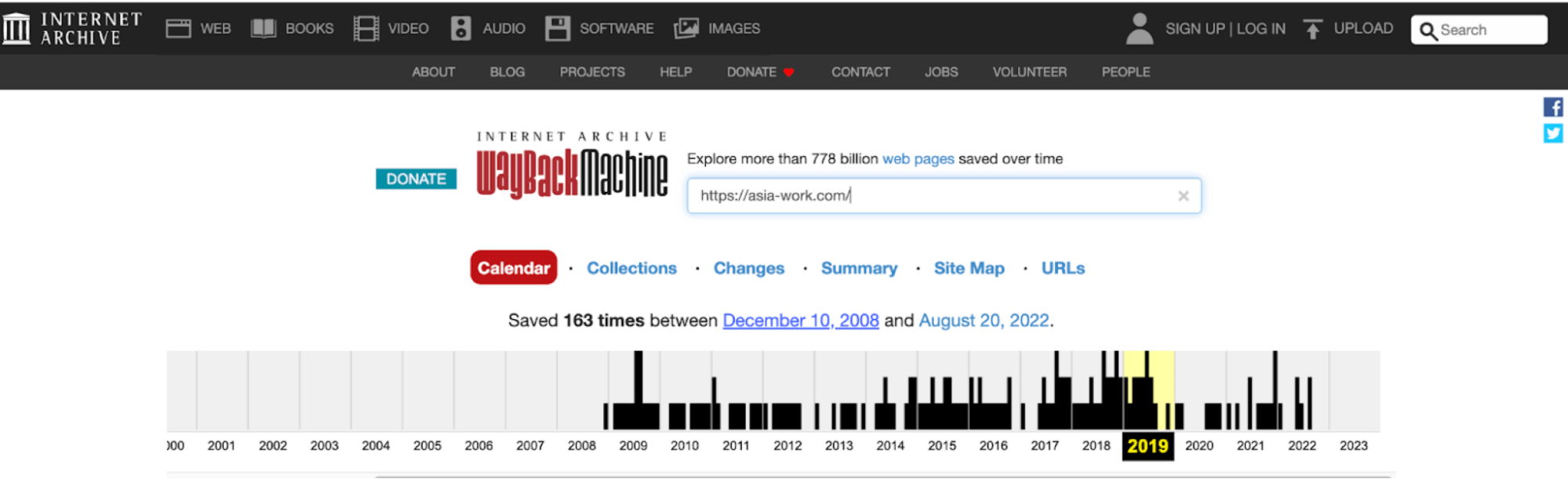
The history of this website looks continuous back to 2008–2009, but the domain expired around August 17, 2019.
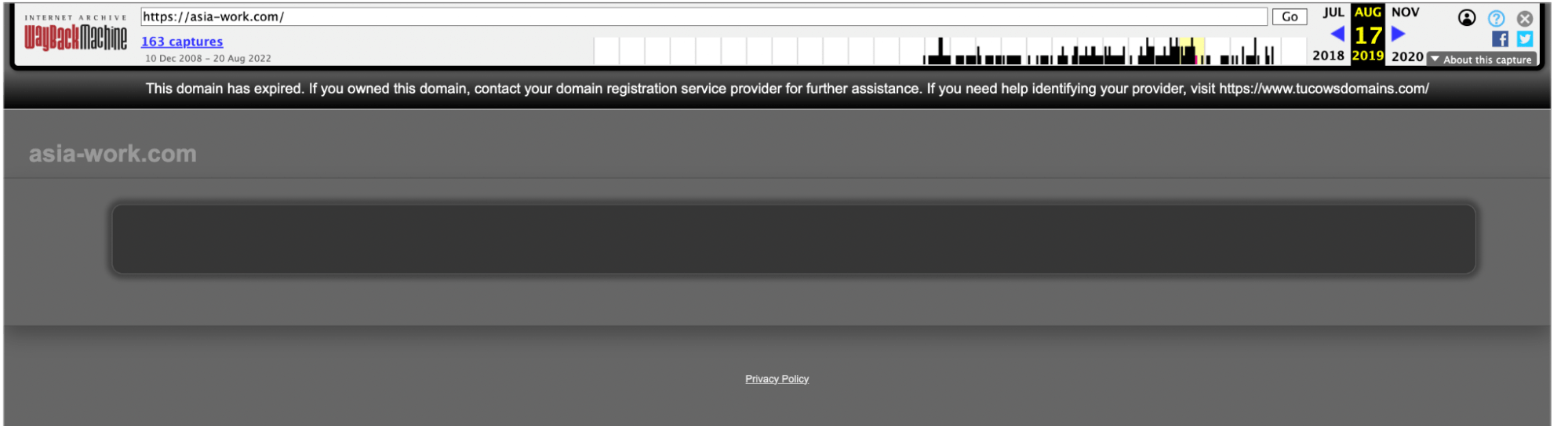
This is how the site used to look in 2009. Even though the design is old-fashioned, it still looks much more legitimate than the present site.
We can see the difference if we compare that with the current site version.
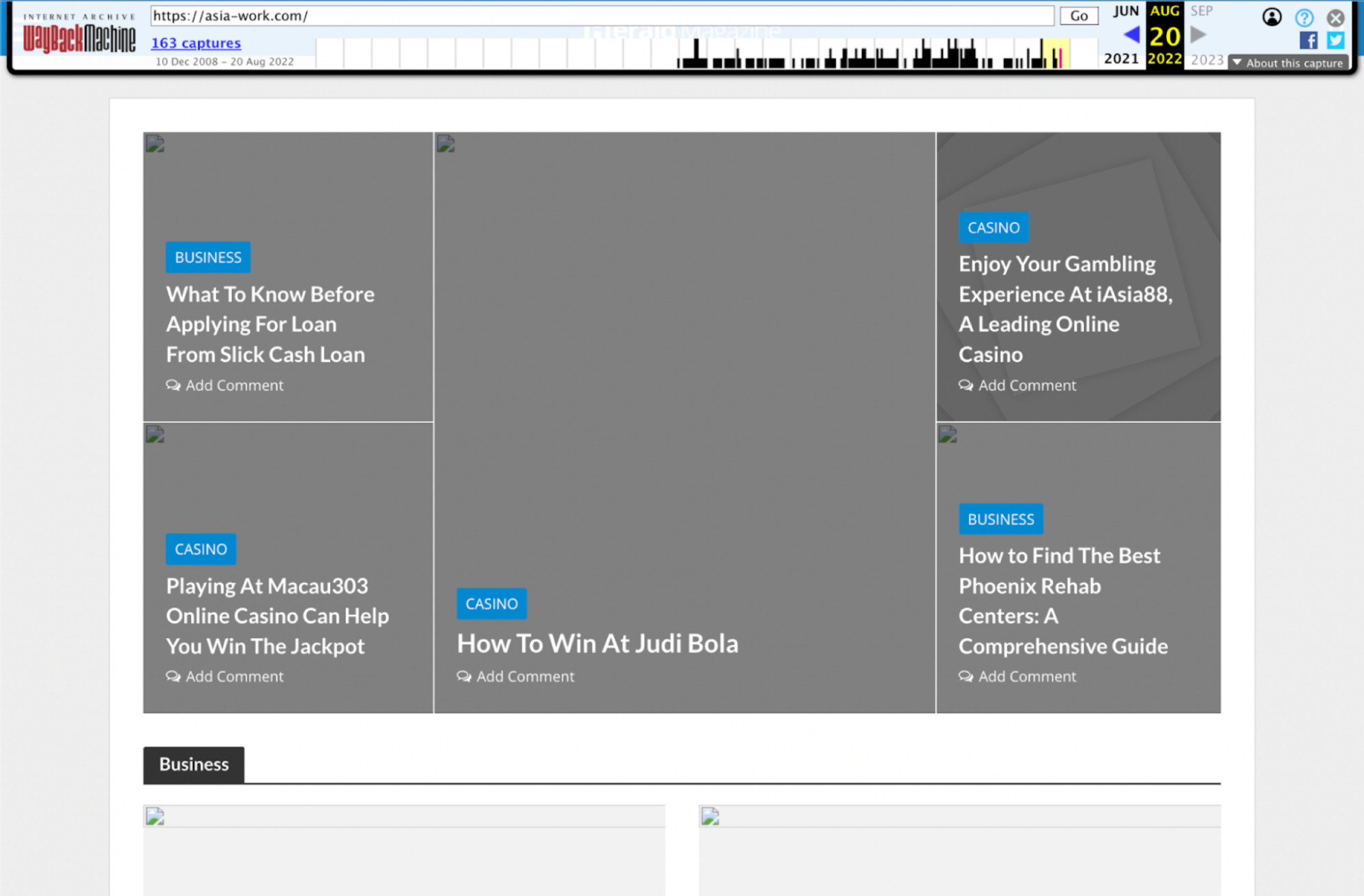
Even though the images aren’t rendered properly, we can see how the text content has changed for the worse.
With the focus of the content changing to topics like “casino,” “gambling,” and “loans,” this immediately looks like a red flag.
Let’s take a closer look at some of the articles on the site to see what we can find.
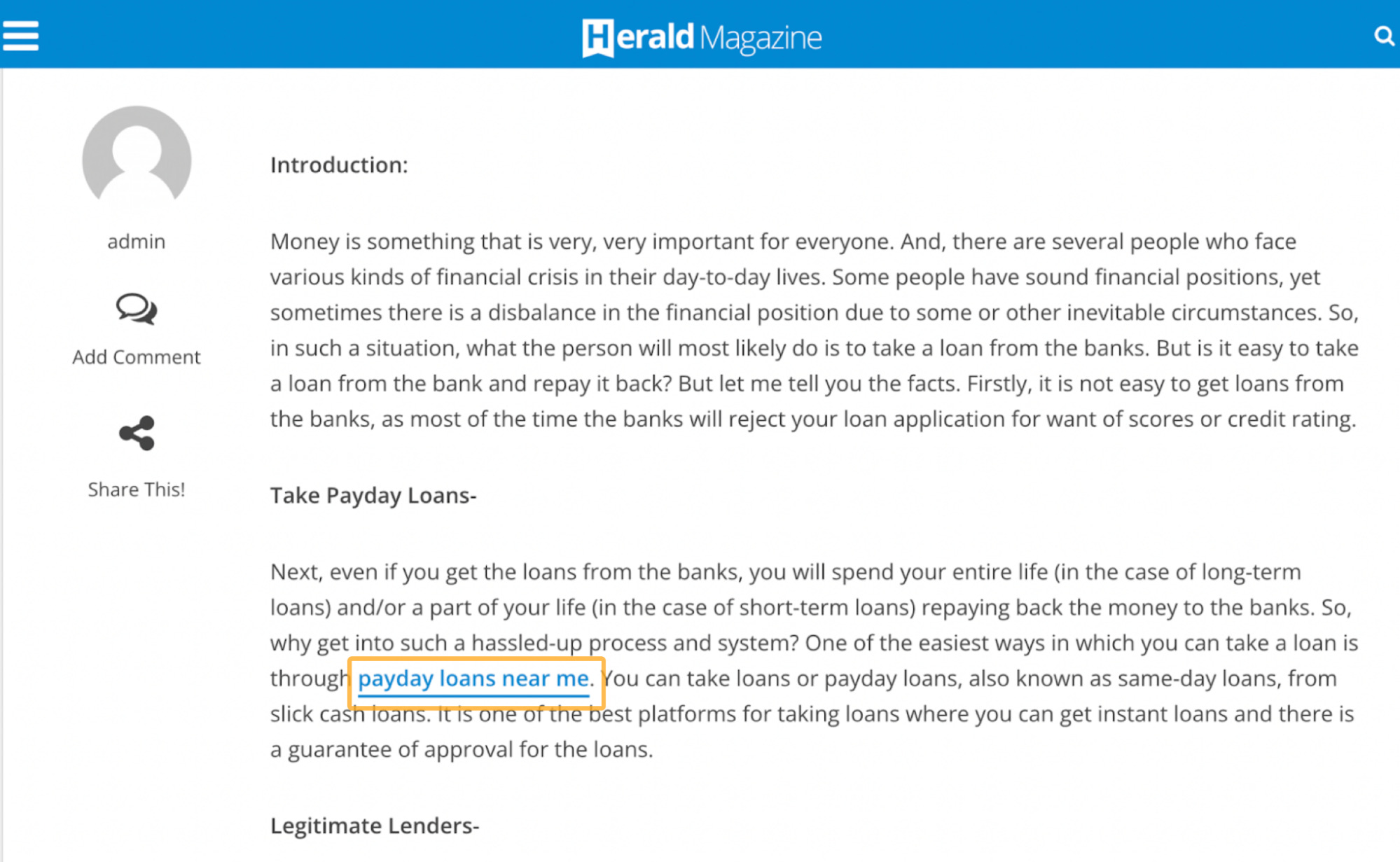
Selling links is against Google’s terms of service. But the above is an example of a link that was probably paid for, with no attempt to hide it.
Here’s another example—this time for a different type of service.
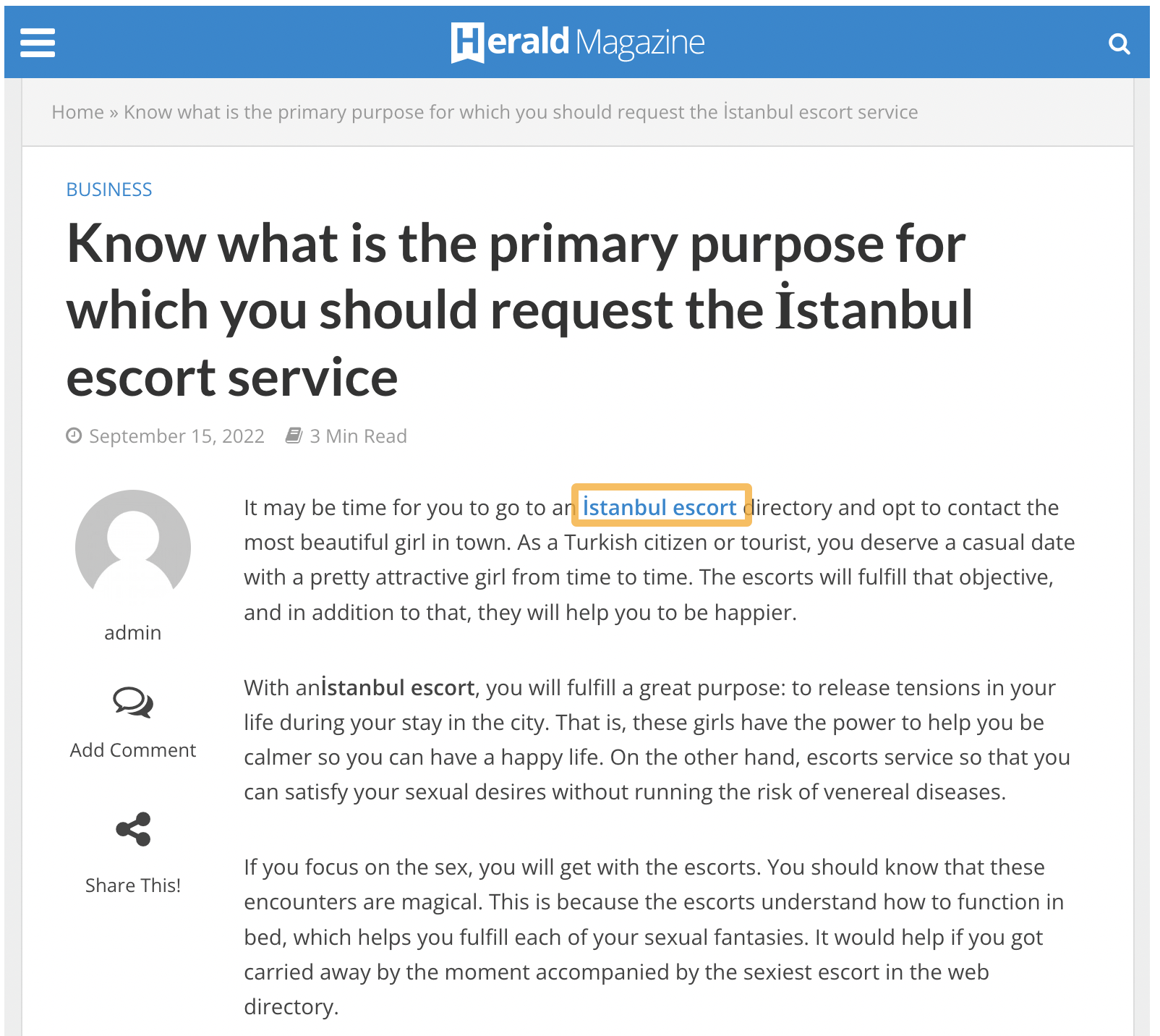
You can see the pattern that is emerging.
It turns out that almost every article in the blog has a single exact-match keyword anchor text link within a body of text, which leads me to believe that links were likely being sold here.
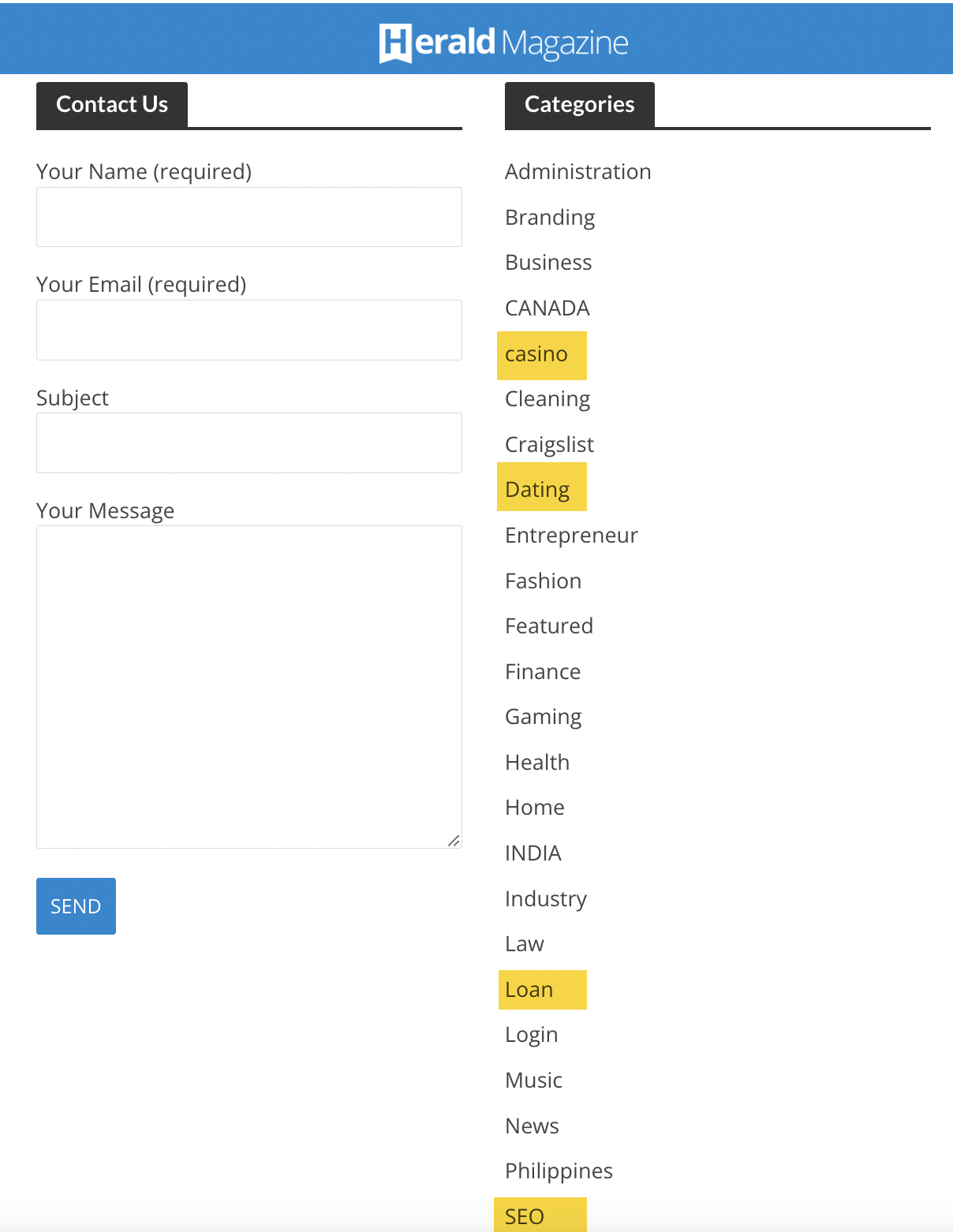
The final nail in the coffin is the website categories—when you see dating, loan, and casino in the same category as SEO, you know that it’s likely links were sold here.
If we turn our attention to the Top pages report in Site Explorer, we can see that one of the primary purposes of the site was to rank for login pages of betting and cockfighting sites.
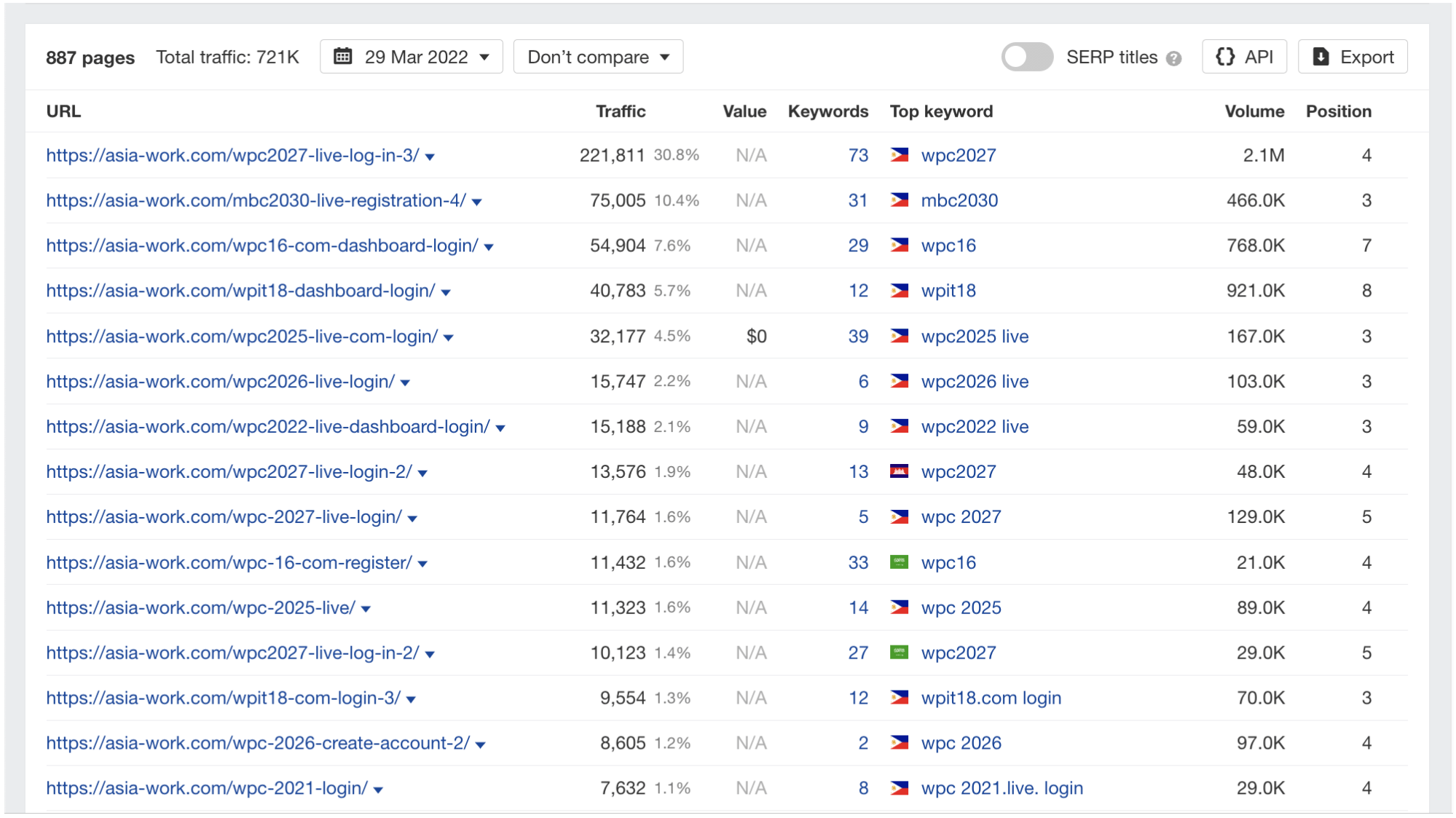
This shows the website’s intent and doesn’t look like a typical website’s top pages.
Links
As we have seen above, the site is an expired domain that has been revived, so it has gained a decent amount of links and authority in that period.
If we look at the Referring domains report, we can see the type of high DR links that this site once had.
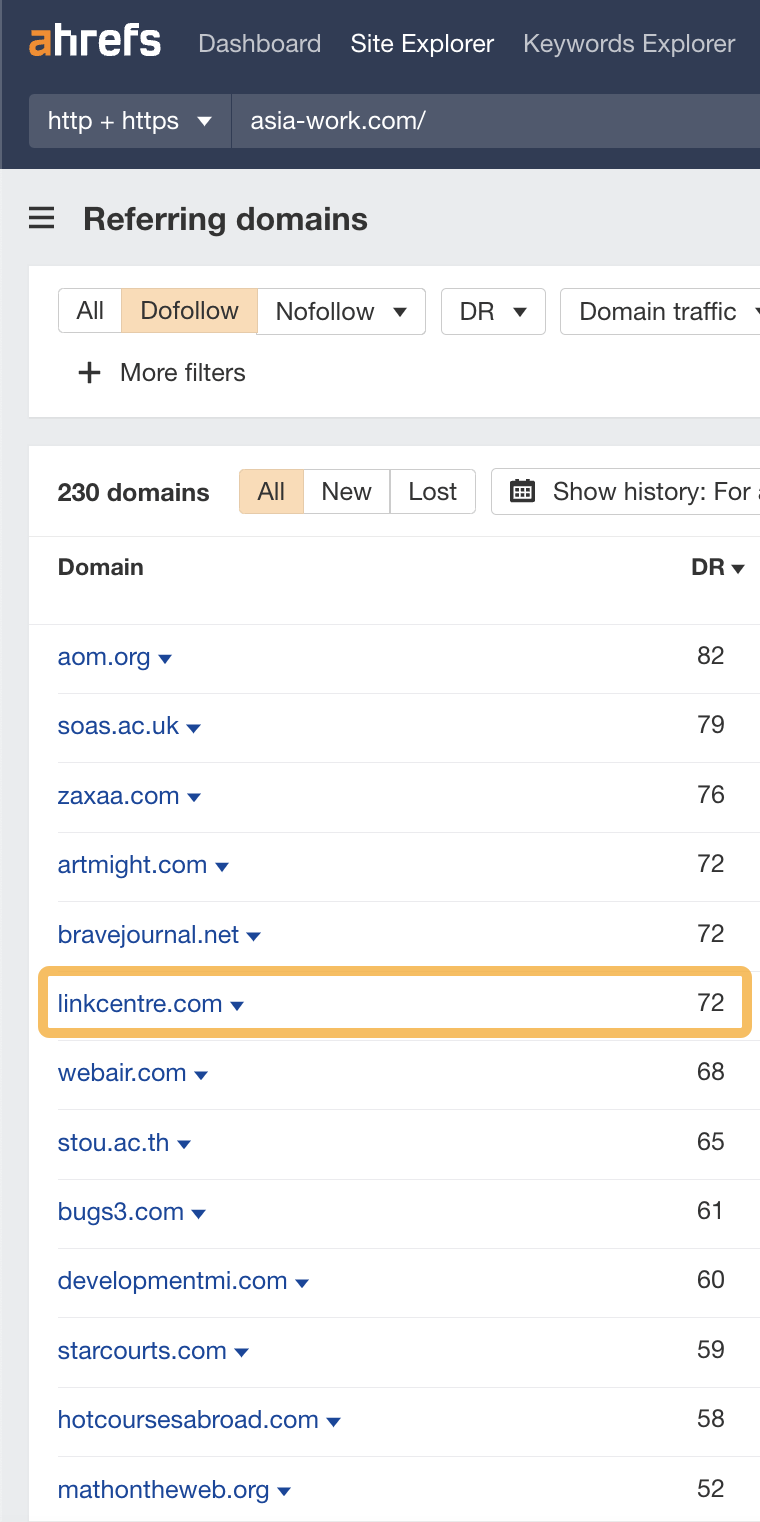
Here’s an example of a directory link (DR 72) from a website called the Link Centre.

Here’s another example of a DR 72 website with a non-related link to our website on the profile page.
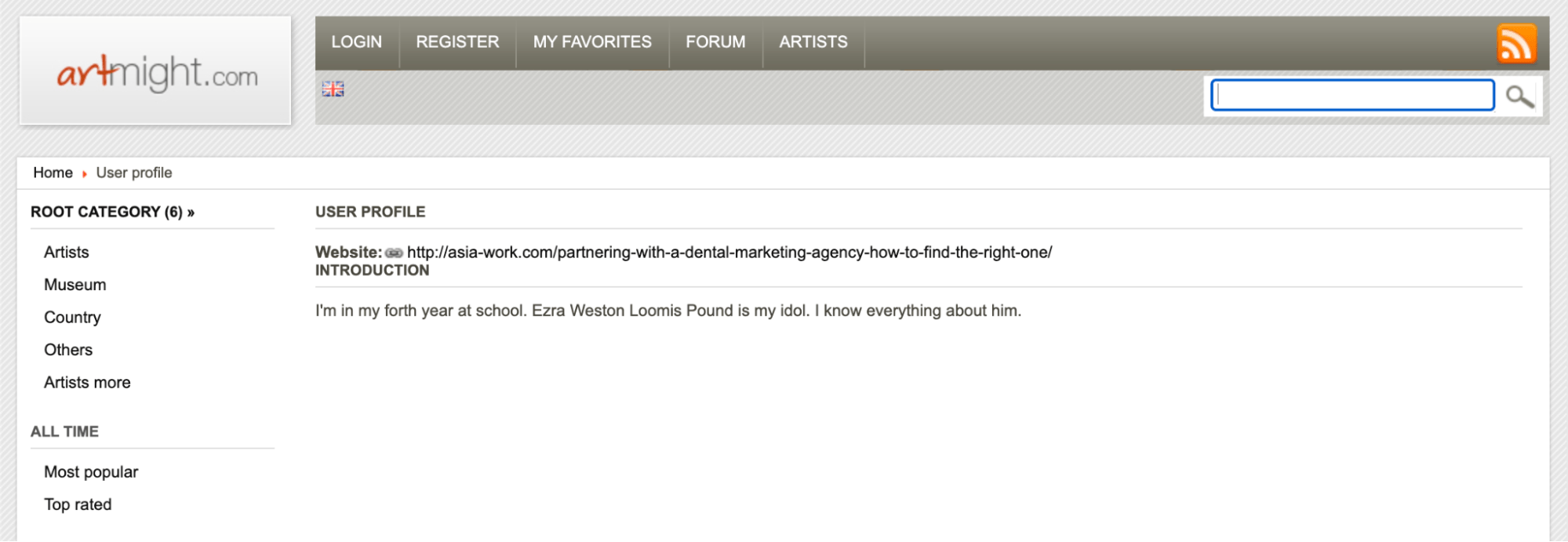
With two university links in the top Referring domains report, you wonder whether these were compromised sites as well.
How did it fail?
Taking a look at Overview 2.0, we can see that there were two critical Google updates in this period.
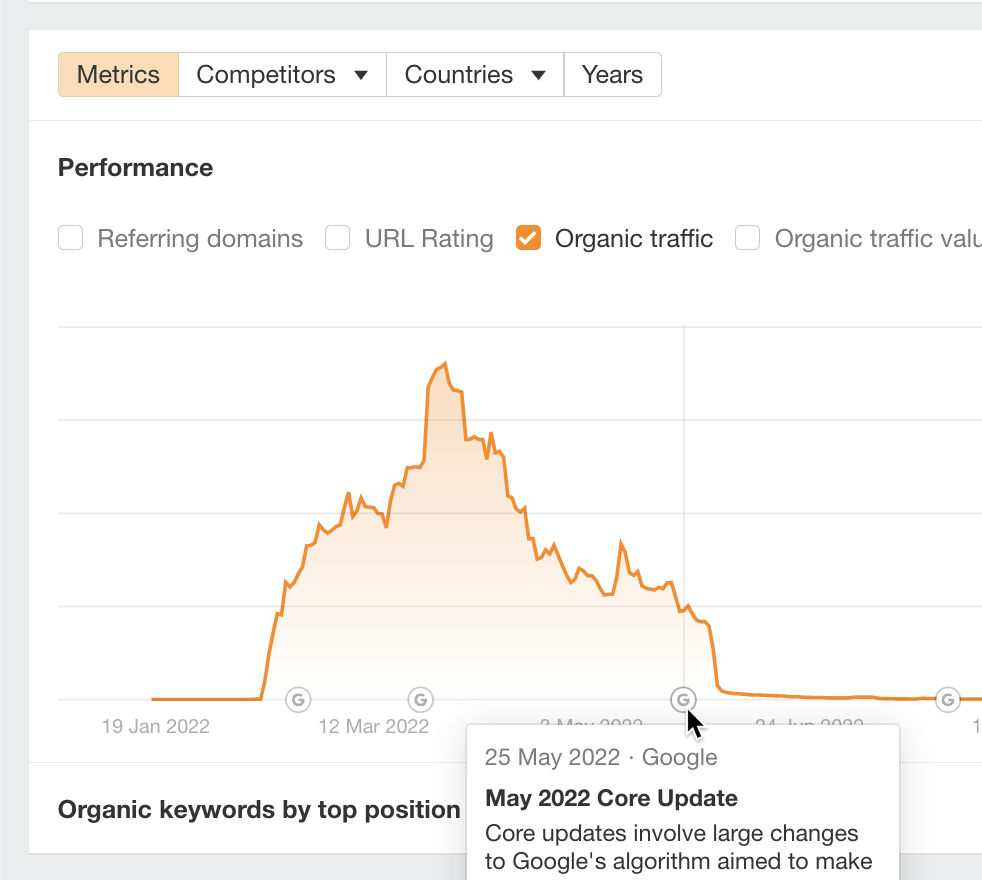
- The first is the Product Reviews Update, which occurred on March 23, 2022. The second is the May 2022 Core Update. Although there isn’t an exact correlation here, these updates could have impacted the site.
- As I suspect they were selling paid links, this could have been another factor. But the gradual fall of the organic traffic chart doesn’t align with the typical look of a manual penalty.
What do you think happened?
Did it really fail to fool Google?
The website didn’t reach the heights of some of our other sites mentioned here, but it did manage to fool Google for around a month.
The site hasn’t been resurrected since, so it’s fair to say that it didn’t fool Google.
Key stats
This next website was created by someone who hated vowels in their domain names.
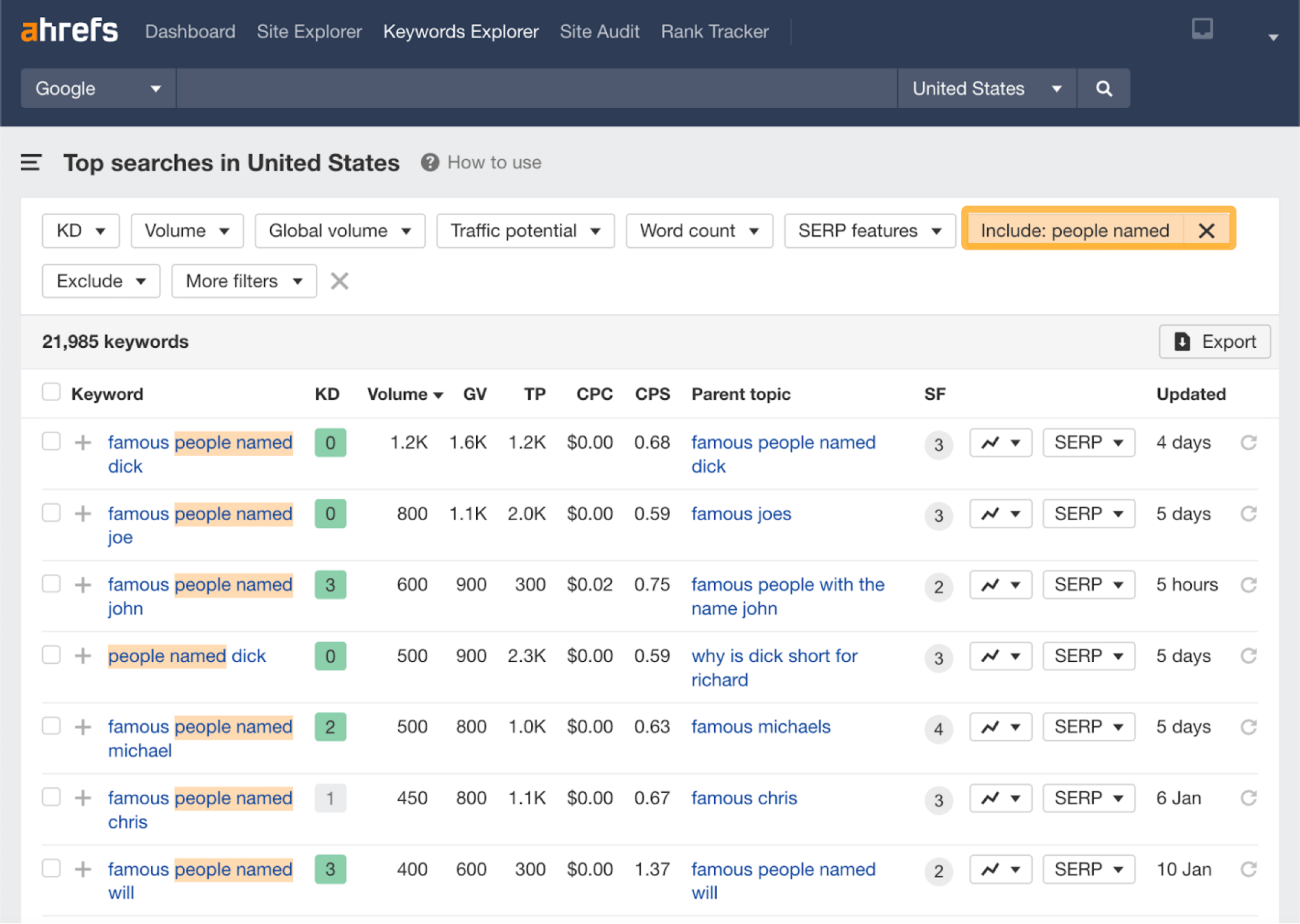
The main idea behind the site seems to have been to create a database-driven site targeting “people named [insert name]” searches.
If we add an “Include” filter into Keywords Explorer, we can see a lot of low-competition searches for this type of query, almost 22,000. This is probably why they decided to create a site around this particular topic.
How did it fool Google?
One of the problems with this site is that most of the content was scraped, and it had several dodgy high DR links pointing to it that didn’t look natural.
Let’s take a closer look at what happened.
Content
If we go to the Top pages report on August 19, we can see that the top page is “People named Dick.”
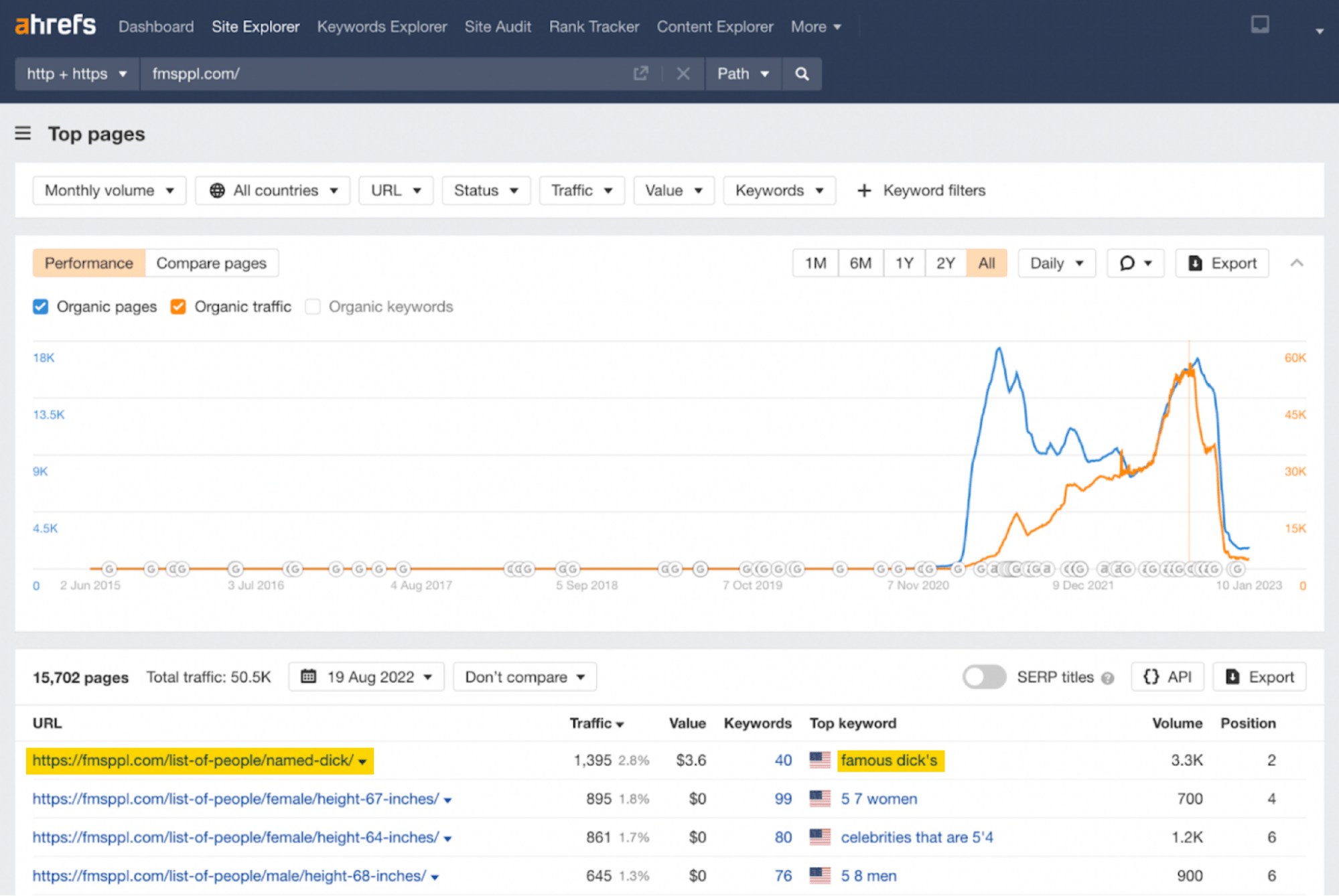
Let’s look at what this page looks like on the site.
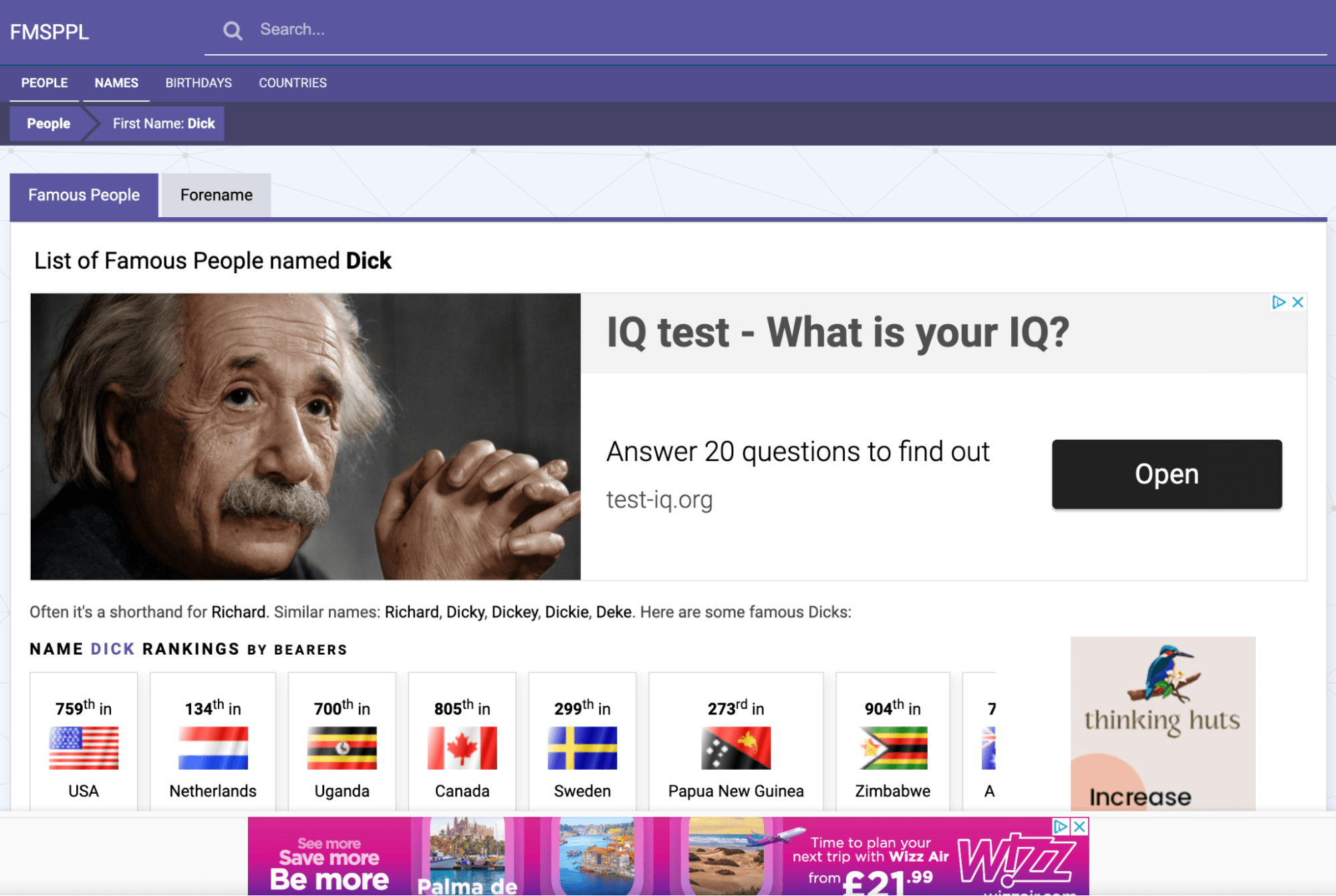
You can see there isn’t that much information here, and most of the content is ads.
Even when we scroll down the page, we can see that it’s a list of people with some key facts about them and nothing more.
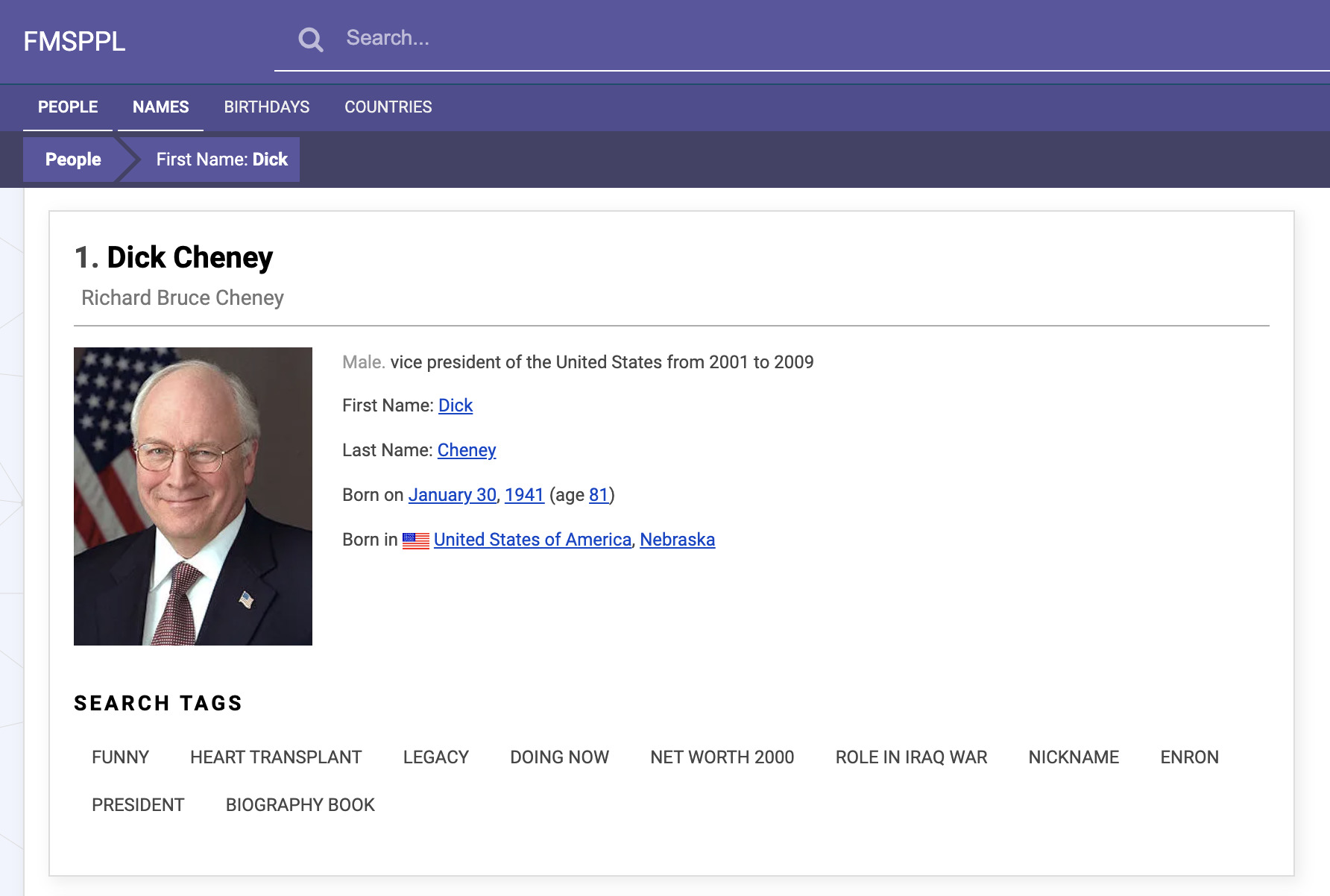
I’ve decided to click on the profile of the number #1 Dick—Dick Cheney.
Pasting the text of his detailed profile in Google brings up a match for Wikipedia.
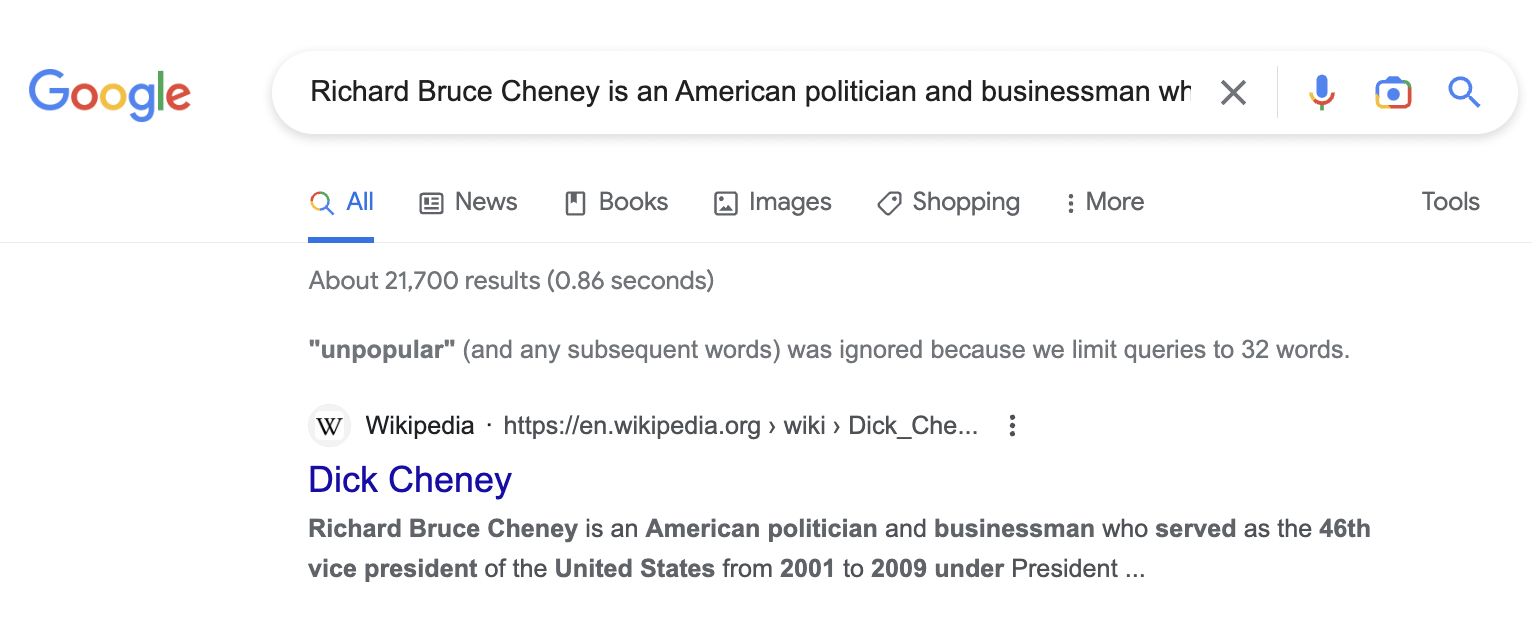
Checking a few other profiles on the site using this method also brings up Wikipedia, so it seems reasonable to conclude that this site was scraping at least some of its content directly from Wikipedia.
Returning to the homepage, you can see the general strategy of the site is quite basic. This is what the site owners did for country selectors:
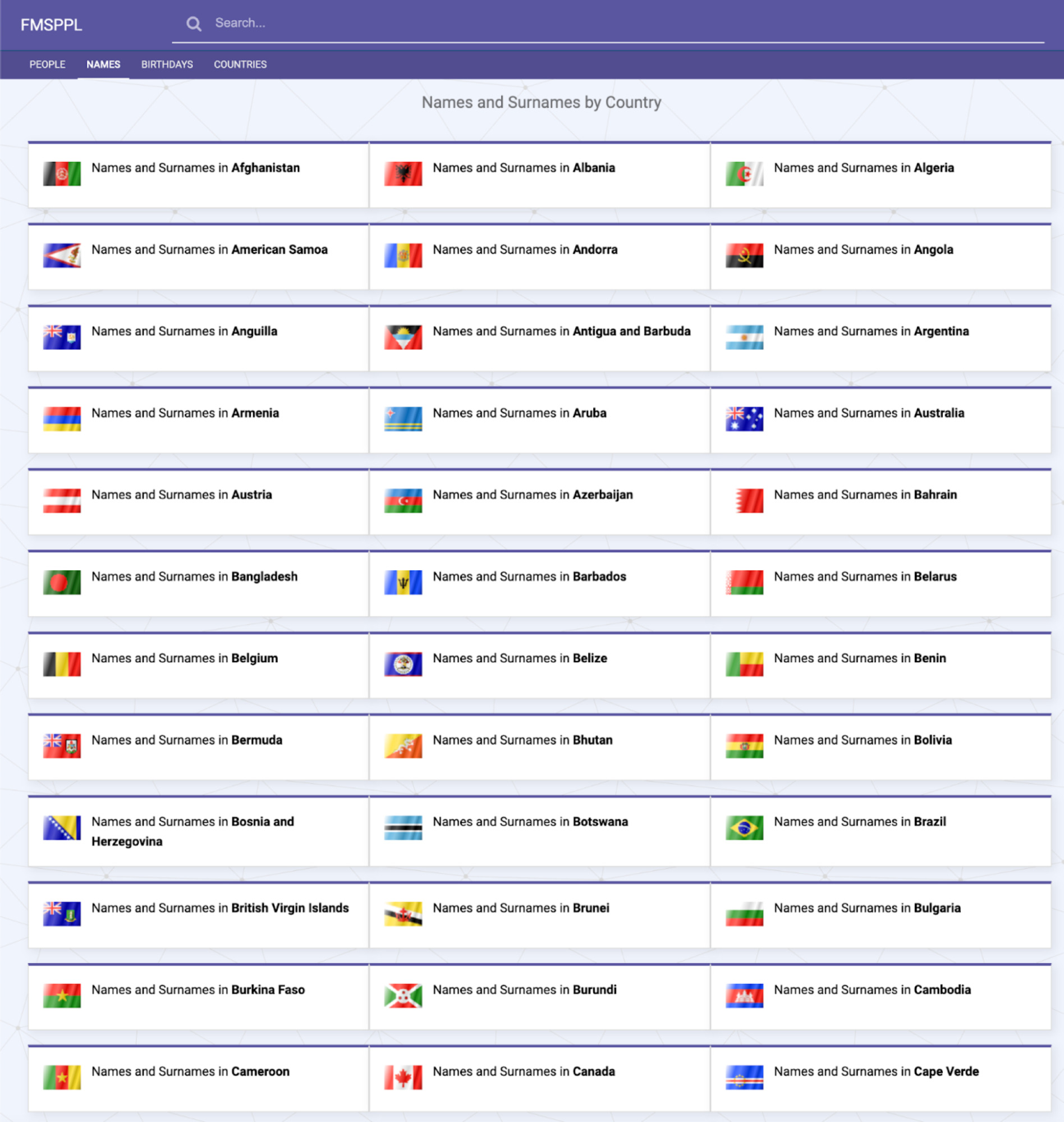
And when it came to birth years, they did something similar.
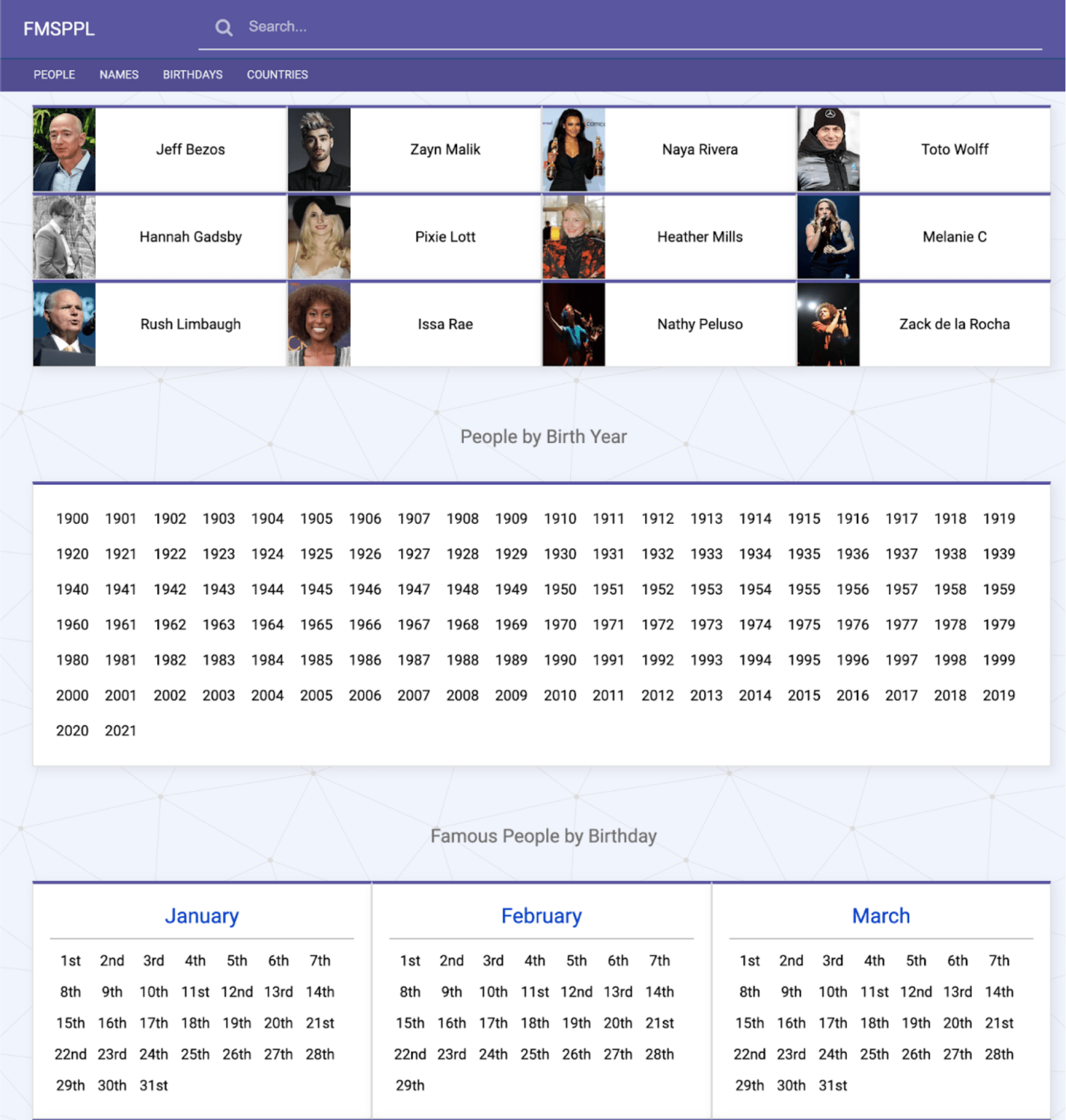
Overall, the content standard is low, and we see a lot of scraped content on this site.
Links
Looking at the Wayback Machine, we can see this is a relatively new site that was started around 2021.
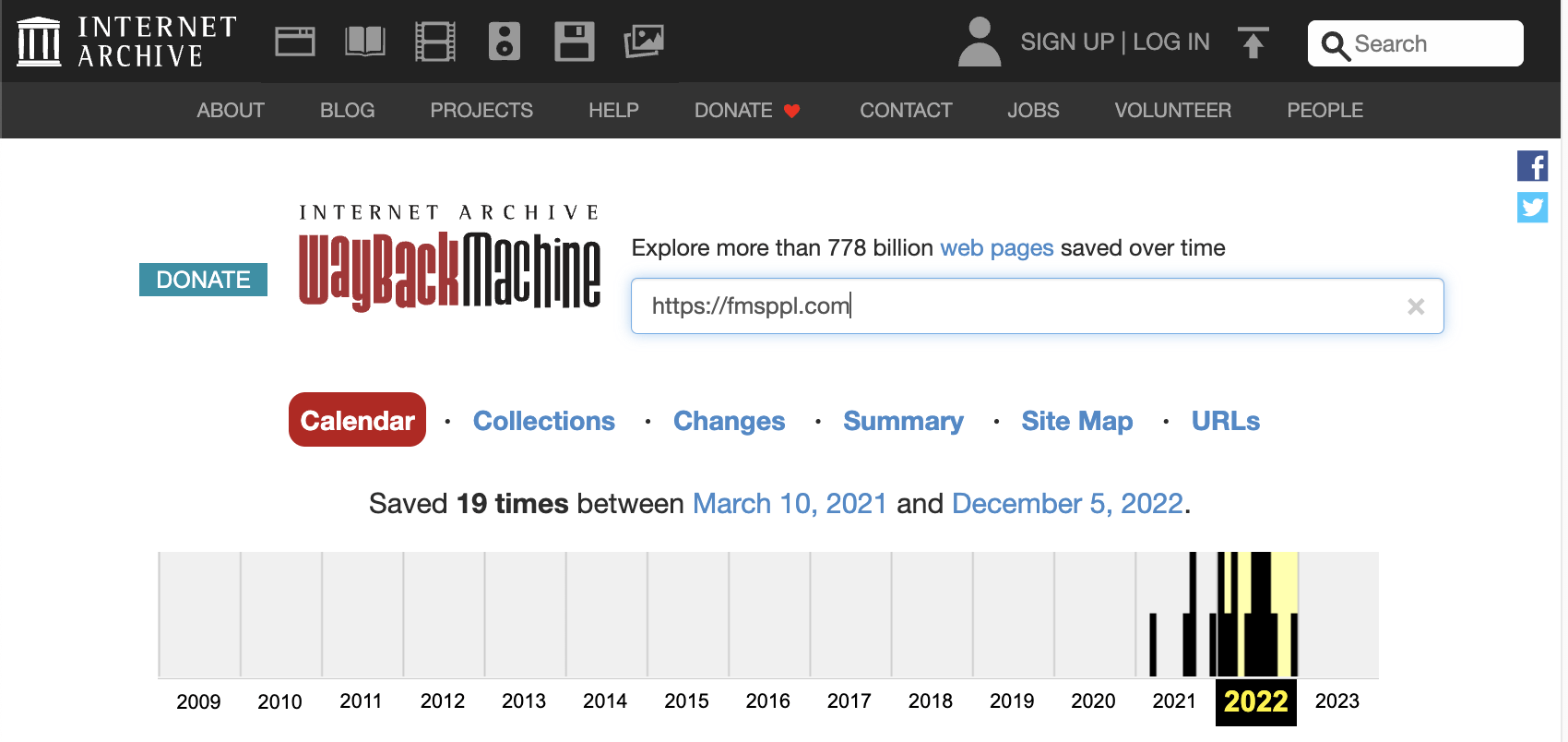
We can assume that it needs some powerful links to get this site off the ground.
There are several suspicious high DR links linking to this site.
To look at them, we can jump into the Referring domains report. I’ve chosen to take a quick look at the DR 82 link, but there are many examples of high DR links with spammy content here.
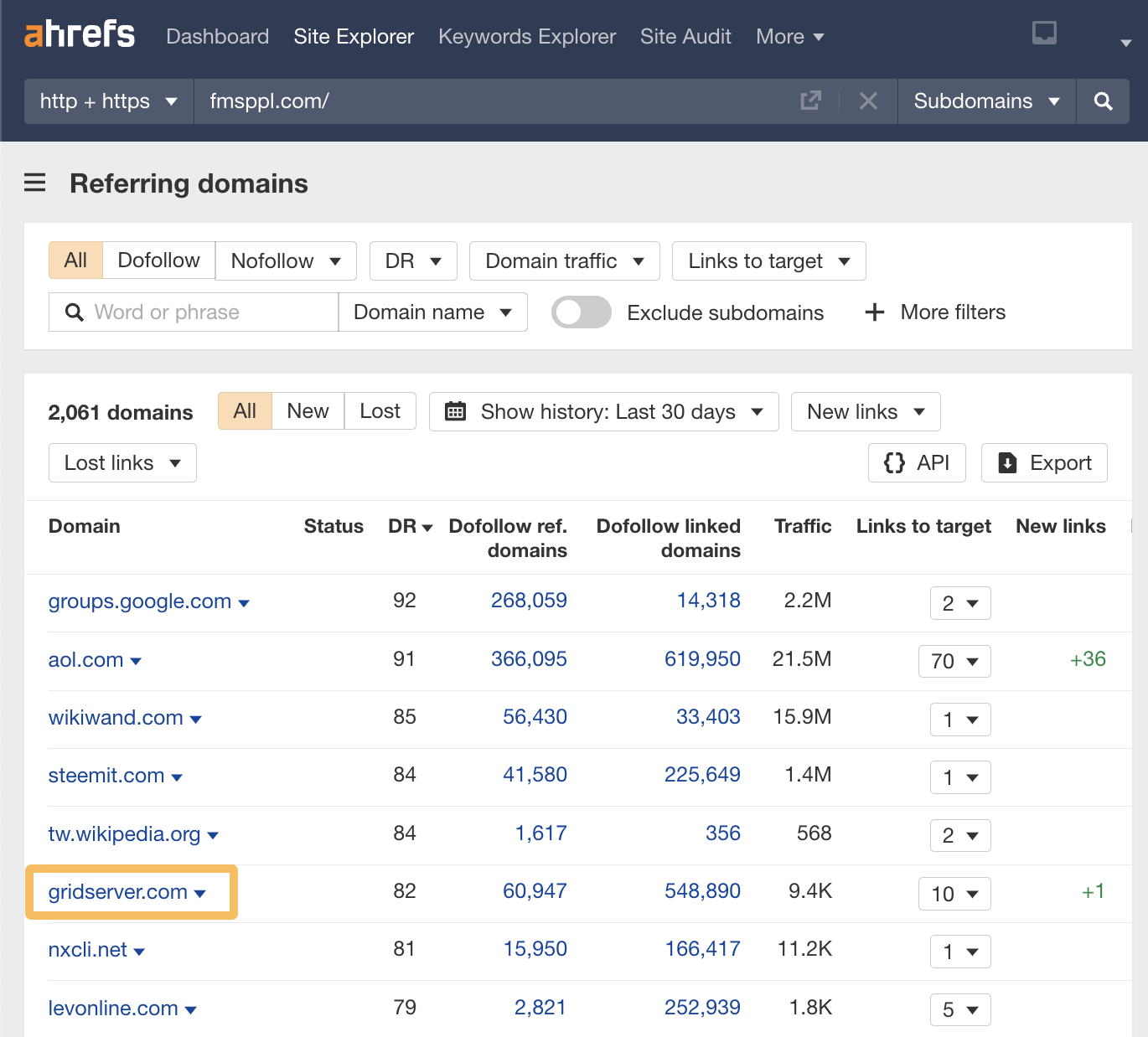
Here’s an example of a DR 82 website linking to this website, and this is what one of the links looks like.

We have just scratched the surface here, but it’s likely that this is not an isolated case. It’s probably fair to say that this looks like a website designed to exploit search engines rather than inform people.
How did it fail?
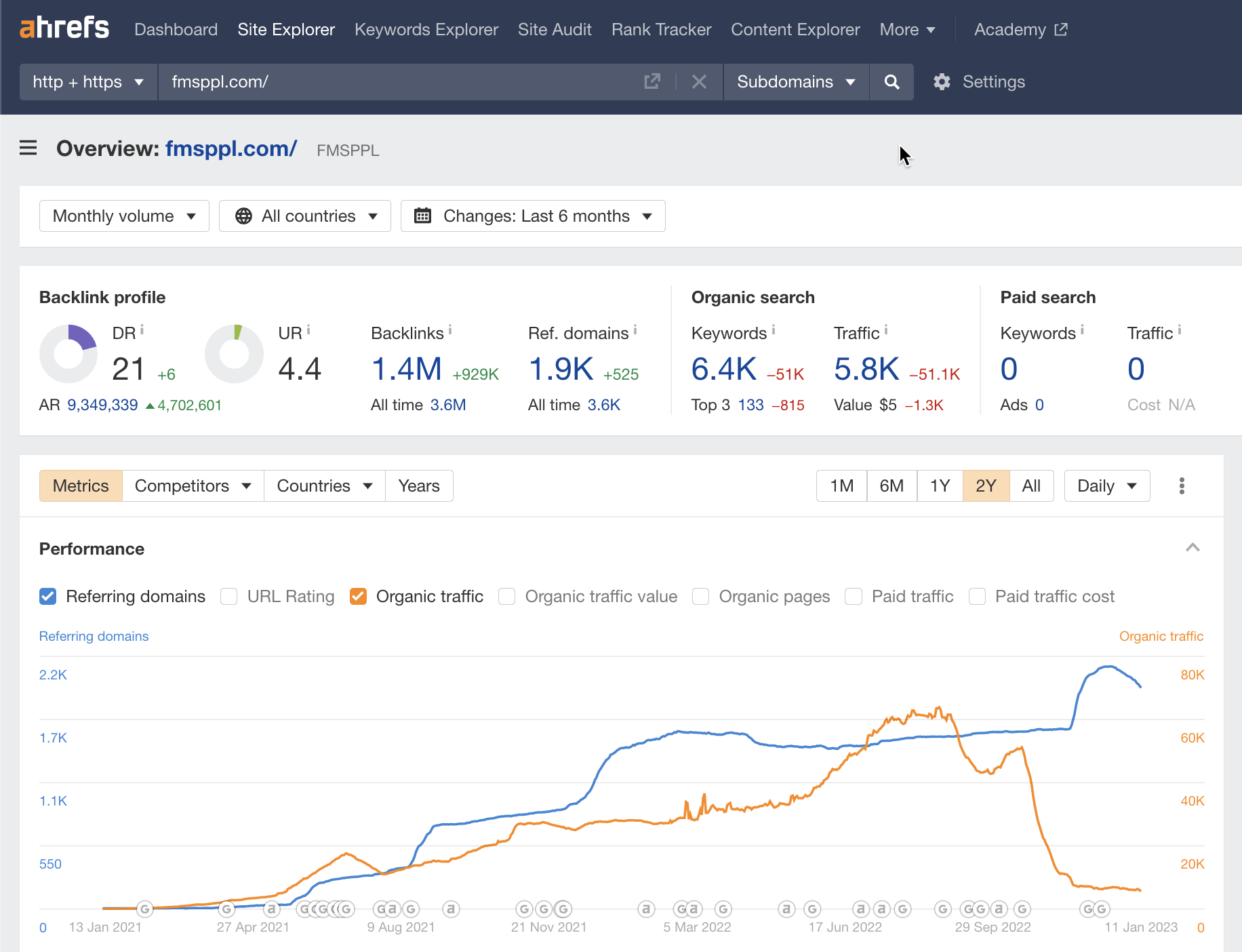
The website appears to have been hit by two Google updates. With neither the content nor the links being that great, I can’t say I am surprised.
I believe that this site was hit by the following:
Sidenote.
Even after the October Spam Update appears to have crushed the site, it seems there was an attempt to build more links to the site.
What do you think happened?
Did it really fail to fool Google?
Yes. I imagine this site’s traffic will be flat-lining shortly.
Key stats
- 22,852 keywords, October 2021
- 195 pages, October 2021
- Total traffic: 8.3M, October 2021
This website allows users to download YouTube videos by simply entering a URL and then hitting the download button—you can see why this type of website would be popular.
How did it fool Google?
The website used an interesting tactic to stay at the top of the search results and try to fool Google repeatedly.
Let’s take a closer look at what happened.
Content
The murky world of YouTube download sites is often filled with ads, surveys, and random floating buttons.
YT5S is, by contrast, a fairly minimal site, which may be how it became popular early on.
When it comes to content for a YouTube download site, there usually isn’t much on the page—this site doesn’t have a blog, for example.
So its main focus is on content to assist people in downloading YouTube videos. Ahrefs’ SEO Toolbar shows us it has just 818 words on the page. Not a lot.
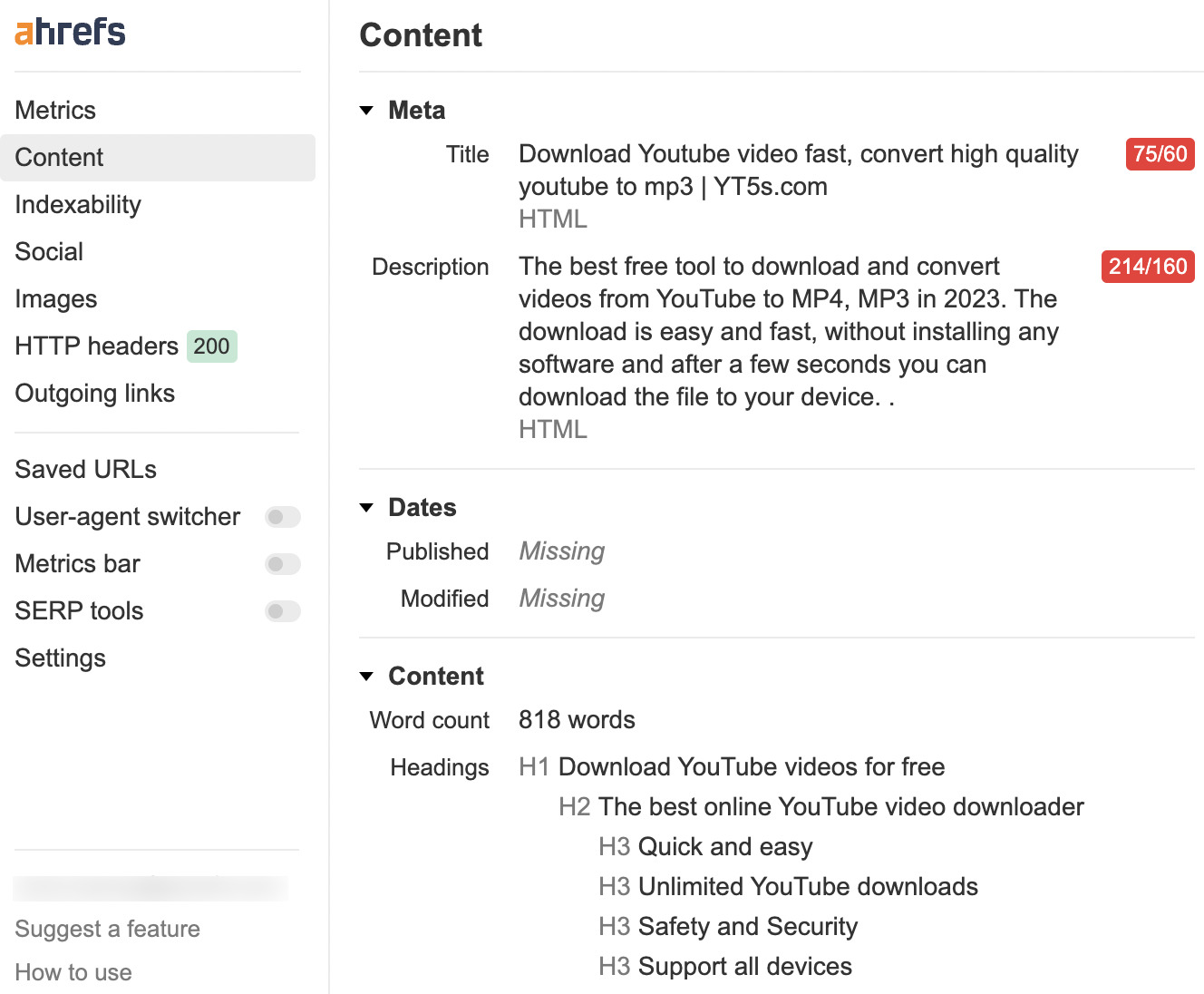
If we look at its Site structure report, we can see that there are many subfolders with numbers at the end.
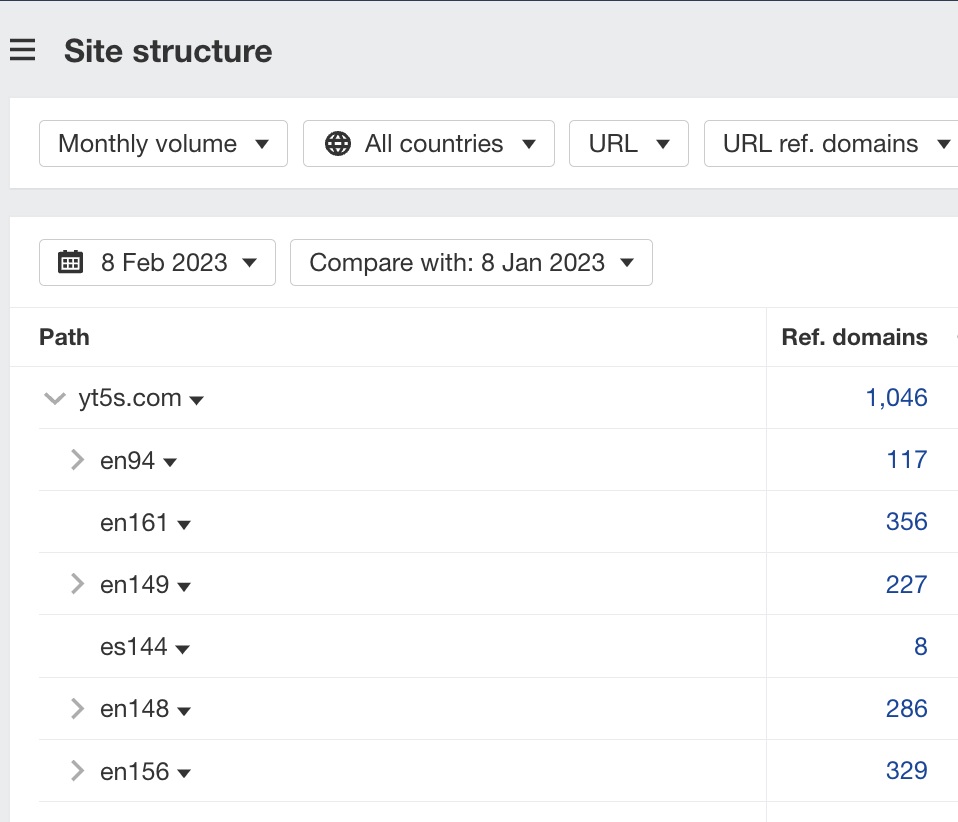
Clicking on the en variations often results in pages that are 301 redirected to the latest version.
As this is such a competitive industry, certain subdomains will get penalized for various reasons. When a subdomain loses traffic, it will be redirected to a new number subfolder.
We see a pattern emerging if we overlap the organic traffic charts for each subfolder.
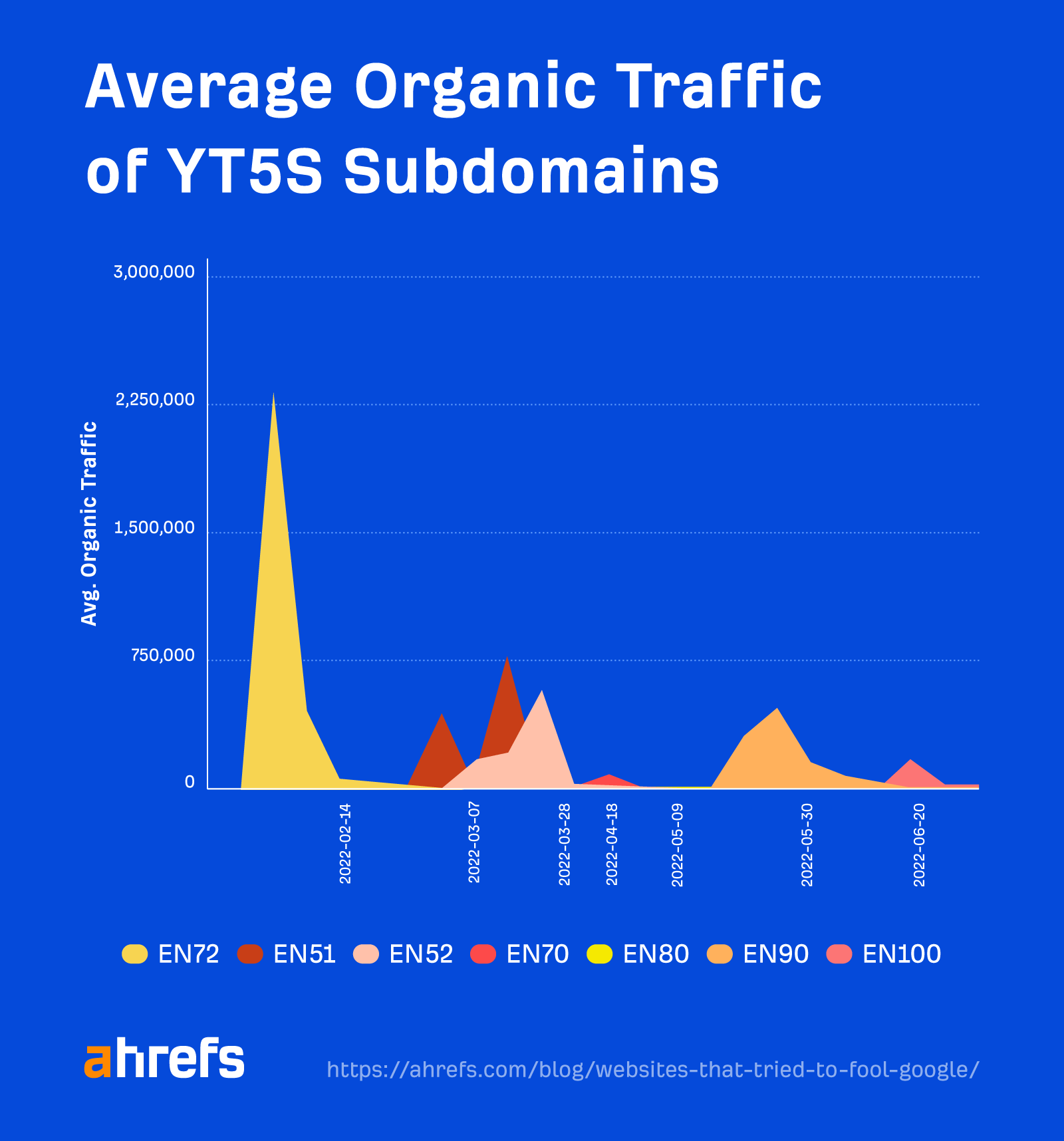
The site’s owners appear to be 301 redirecting the entire website to a new subfolder once the old subfolder has lost traffic.
This site is not alone in this tactic. Looking at the Position history in Ahrefs’ Keywords Explorer, we can see that some of the other websites in this category have cottoned on to this strategy and are doing a similar thing, judging by some of the names of the subfolders.

Links
With a site on this topic, it will be shared widely and linked to naturally. Most of the links appear to be relatively natural.
How did it fail?
The cut-throat nature of this SERP means that it’s highly competitive. The site owners thought they had found a way to get around the loss in traffic by redirecting the website into a new subfolder. It worked for a while. But over time, the impact diminished.
Did it really fail to fool Google?
Yes, for now. But this method will continue being used to try and fool Google in the short term.
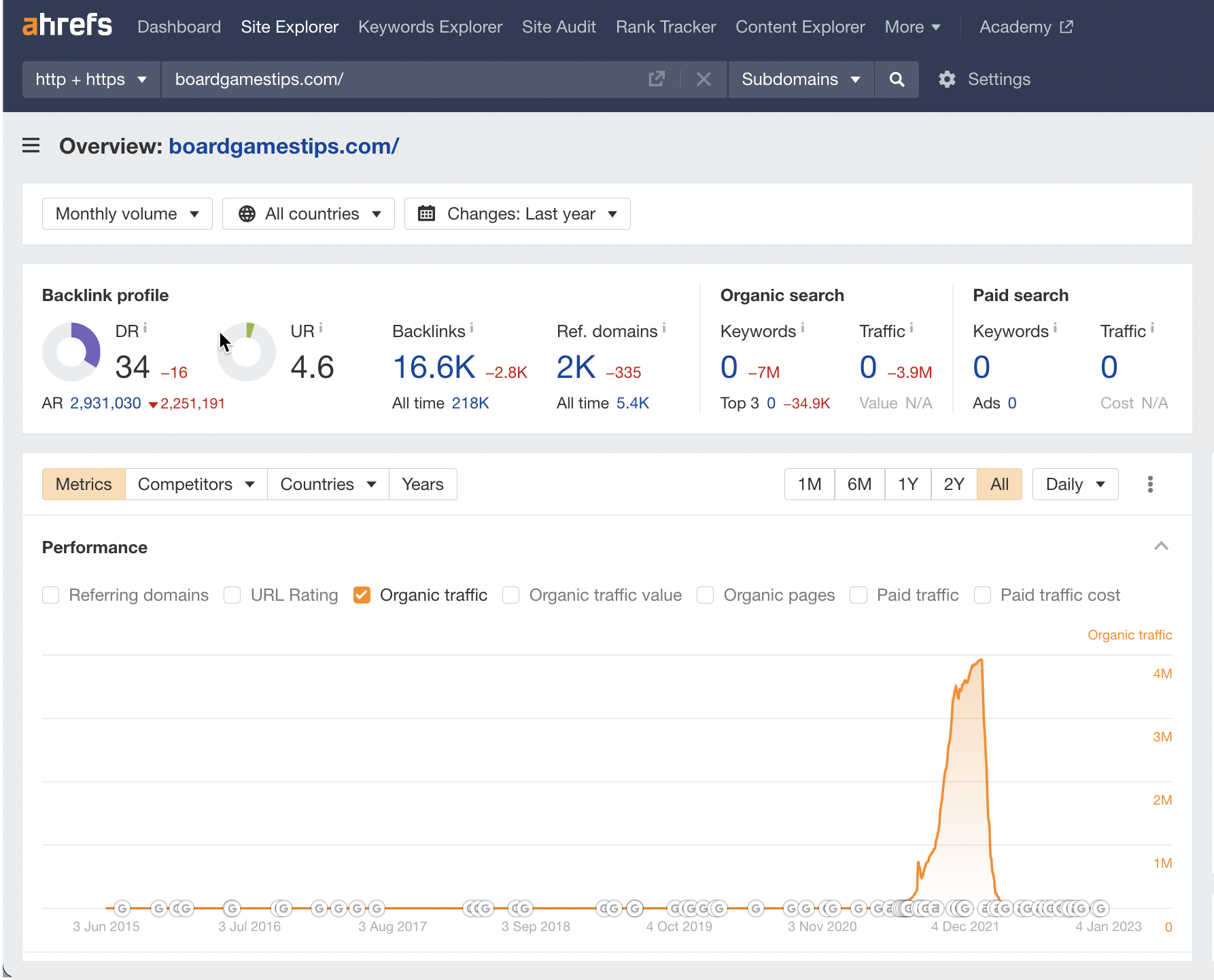
Key stats
- 6,355,904 keywords, January 2022
- 694,334 pages, January 2022
- Total traffic: 3.9M, January 2022
In case you were wondering, this site didn’t have much to do with board game tips.
Despite this, it reached 3.9 million organic traffic during its peak through low-quality content and some dubious-looking high DR links.
How did it fool Google?
It seems to have taken PAA scraping to the extreme, sometimes veering way off topic in the process on some of the posts.
From my research, it also had some suspicious-looking links from some unlikely sources.
Let’s take a closer look at what happened.
Content
Using the Top pages report, we can look at some of the articles.
Let’s highlight a section of the “Organic traffic” graph to select the top pages between two dates.
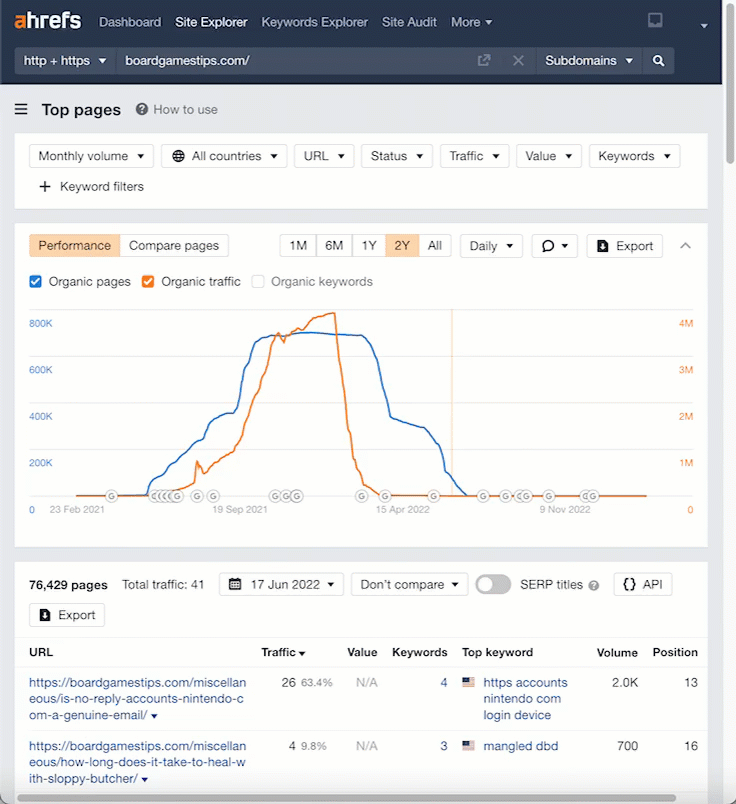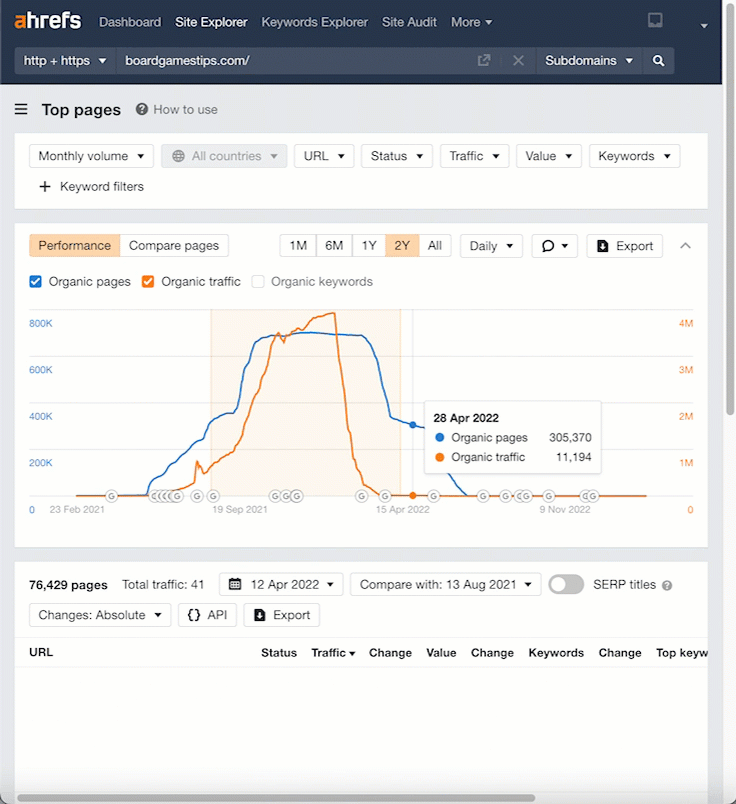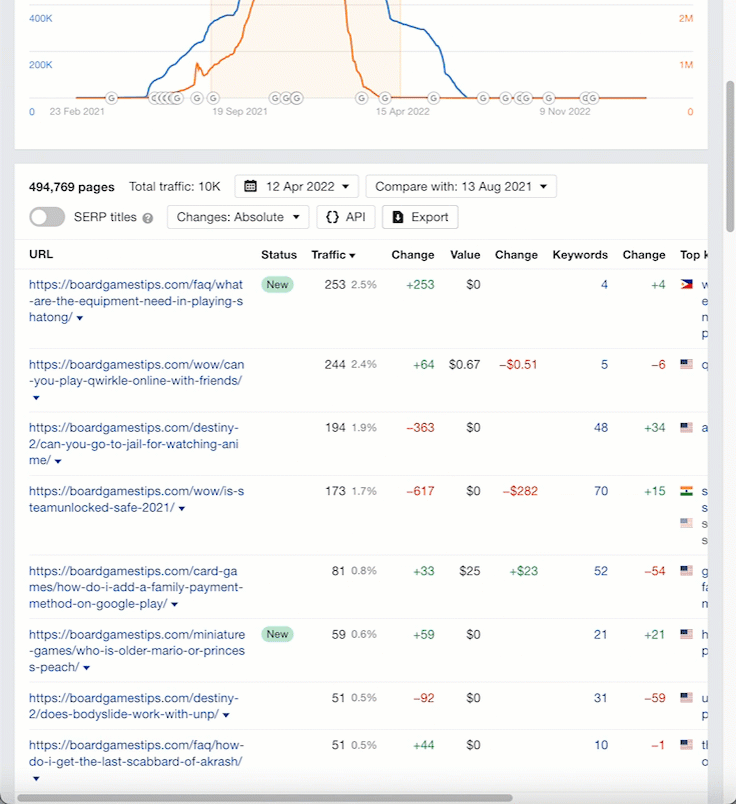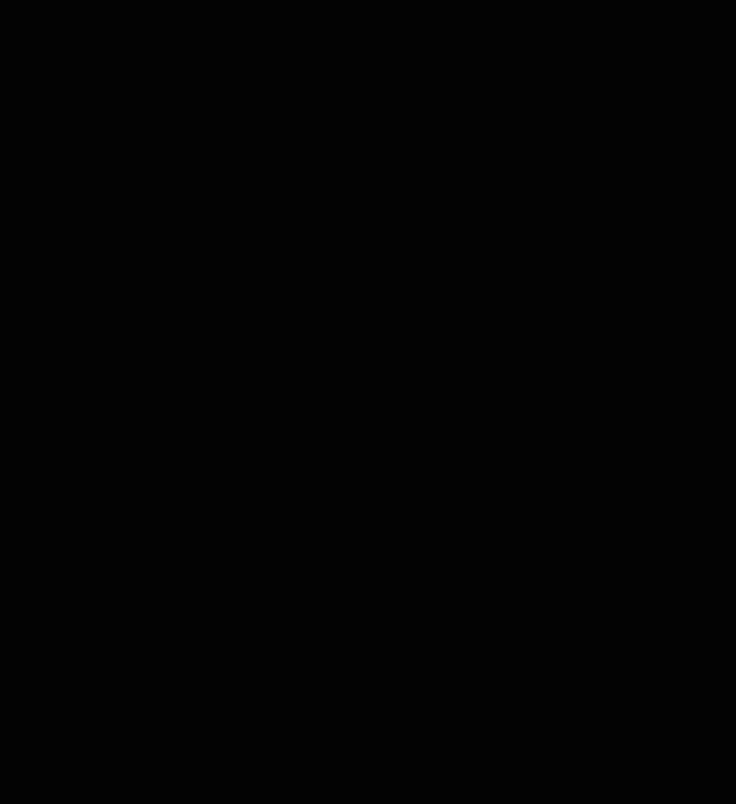
Let’s click through to the Wayback Machine again and take a look at one of the URLs. (I’ve picked a random URL with Wayback history.)
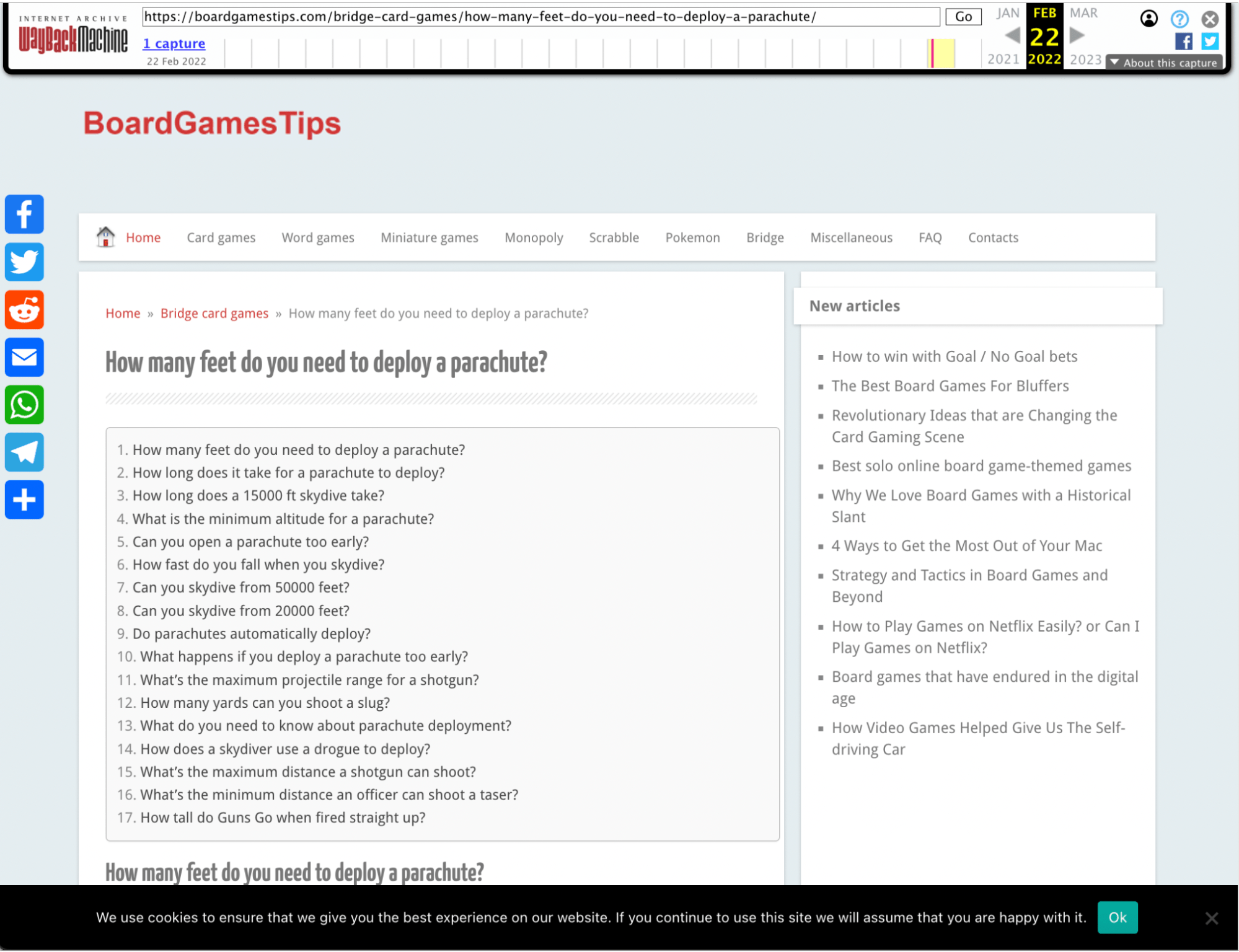
Even from the table of contents, we can see that this is PAA spam. The subheadings wildly switch from deploying parachutes to shotguns, tasers, and guns.
Scrolling down the page further, we get the familiar three or four lines of text followed by a heading.
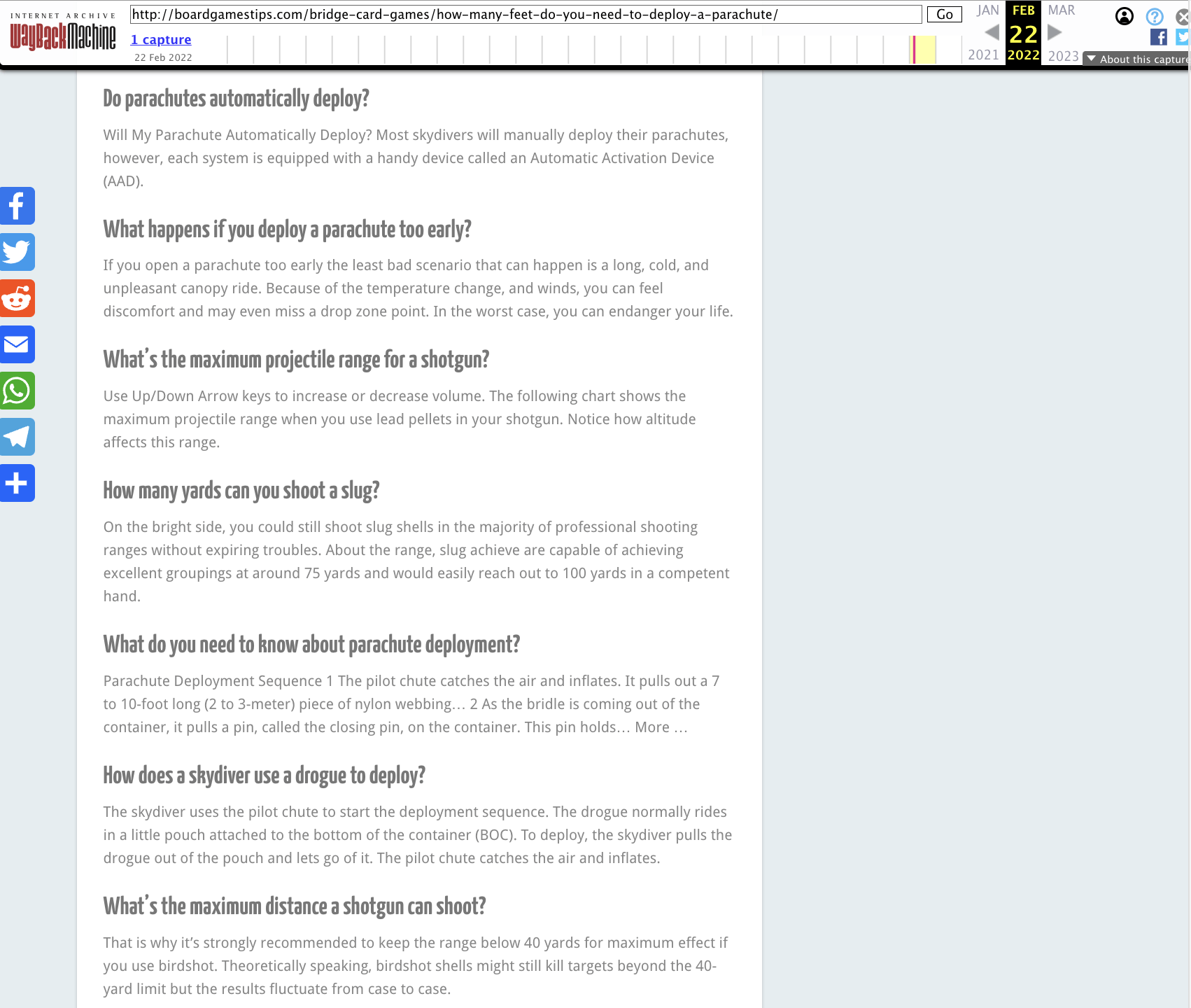
If we paste the content into Google, we can understand whether it’s scraped.
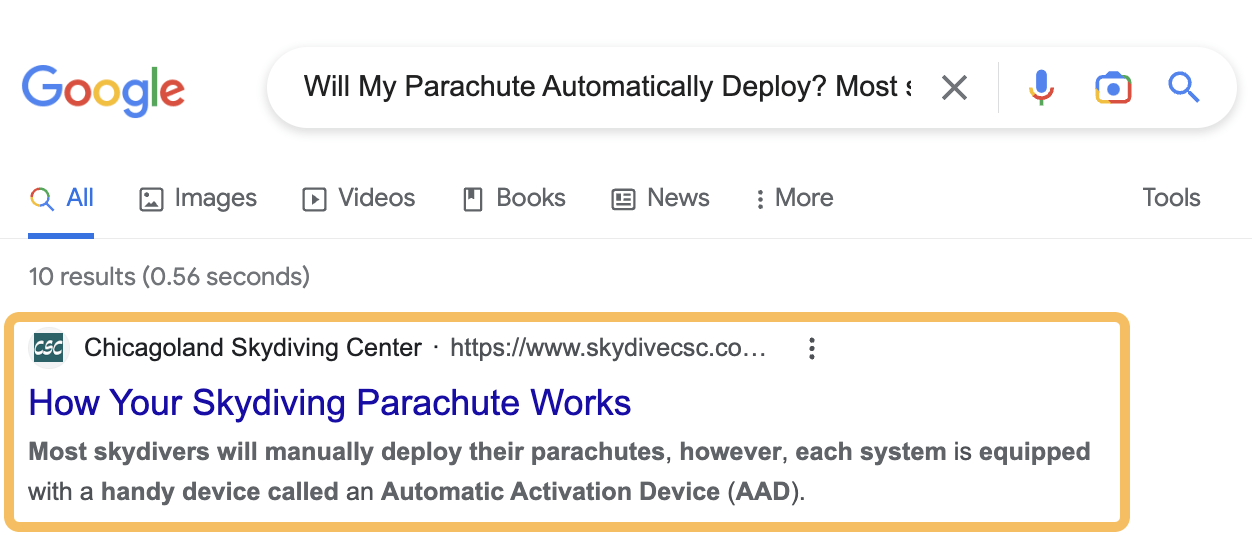
It looks to me like this answer came from this site.
Turning to Twitter, we can see that we are not the only people to have discovered this.
We can conclude then that the content standard for this site is again incredibly low. But it was enough to fool Google at one point.
Links
There is a horror show of links from this site.
Our old friend, Grid Server (DR 82), is linking to the site again.
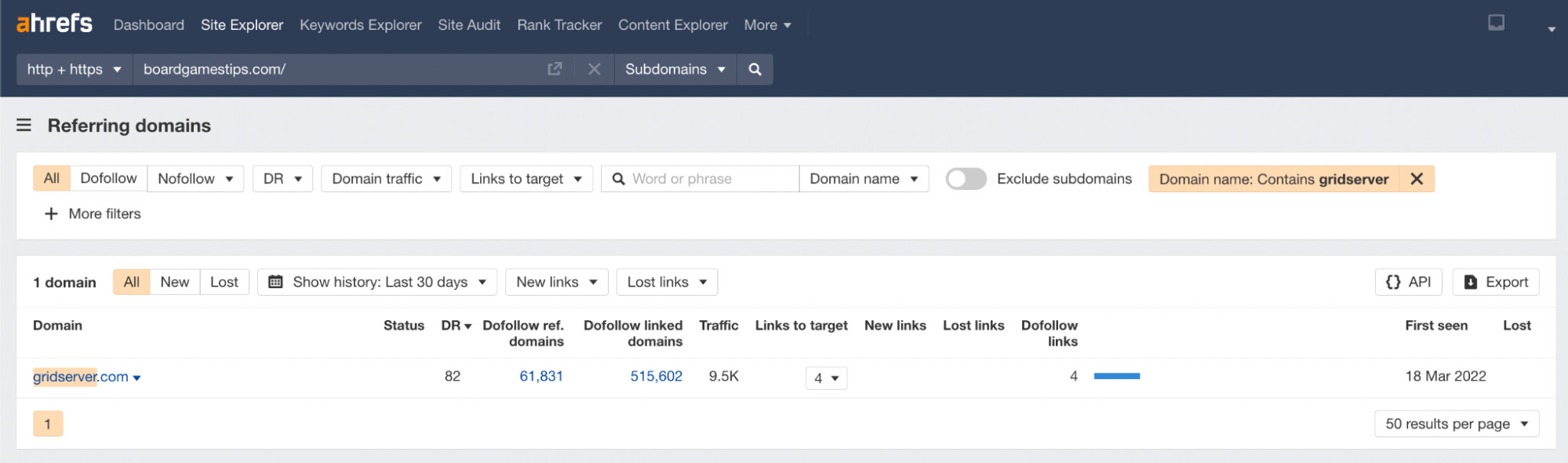
Here’s another reference to a broken link to this DR 81 domain, which you may remember from earlier on.
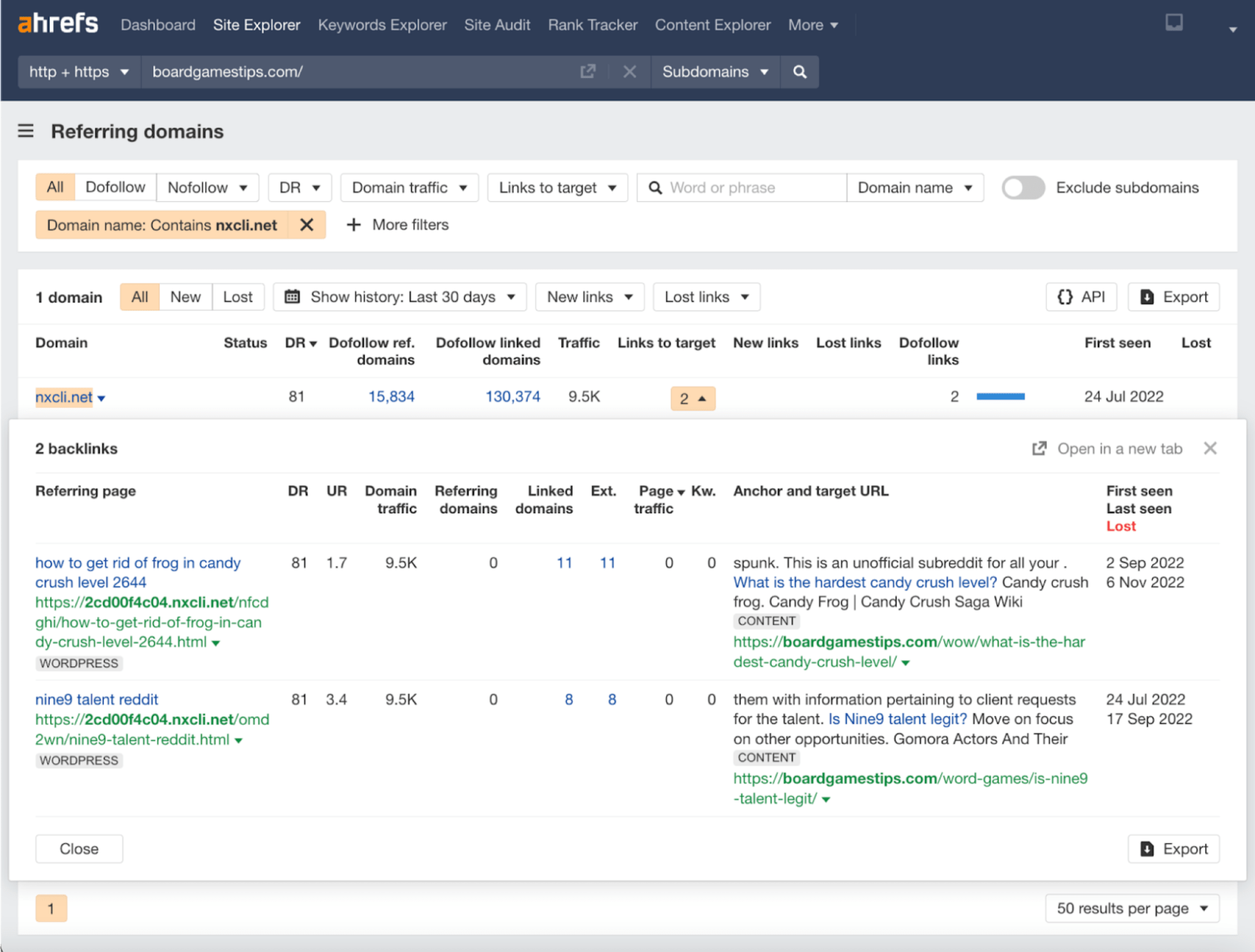
Finally, here’s a dubious-looking link from an unlikely source—Swansea University (UK) (DR74). It’s one of the domains we saw also linking to our third website.

Should these other academic sites be concerned?
How did it fail?
This site has it all—bad links and scraped content. As the organic traffic drop doesn’t tie in with any specific Google algorithm updates, the website may have received a manual penalty.
What do you think happened?
Did it really fail to fool Google?
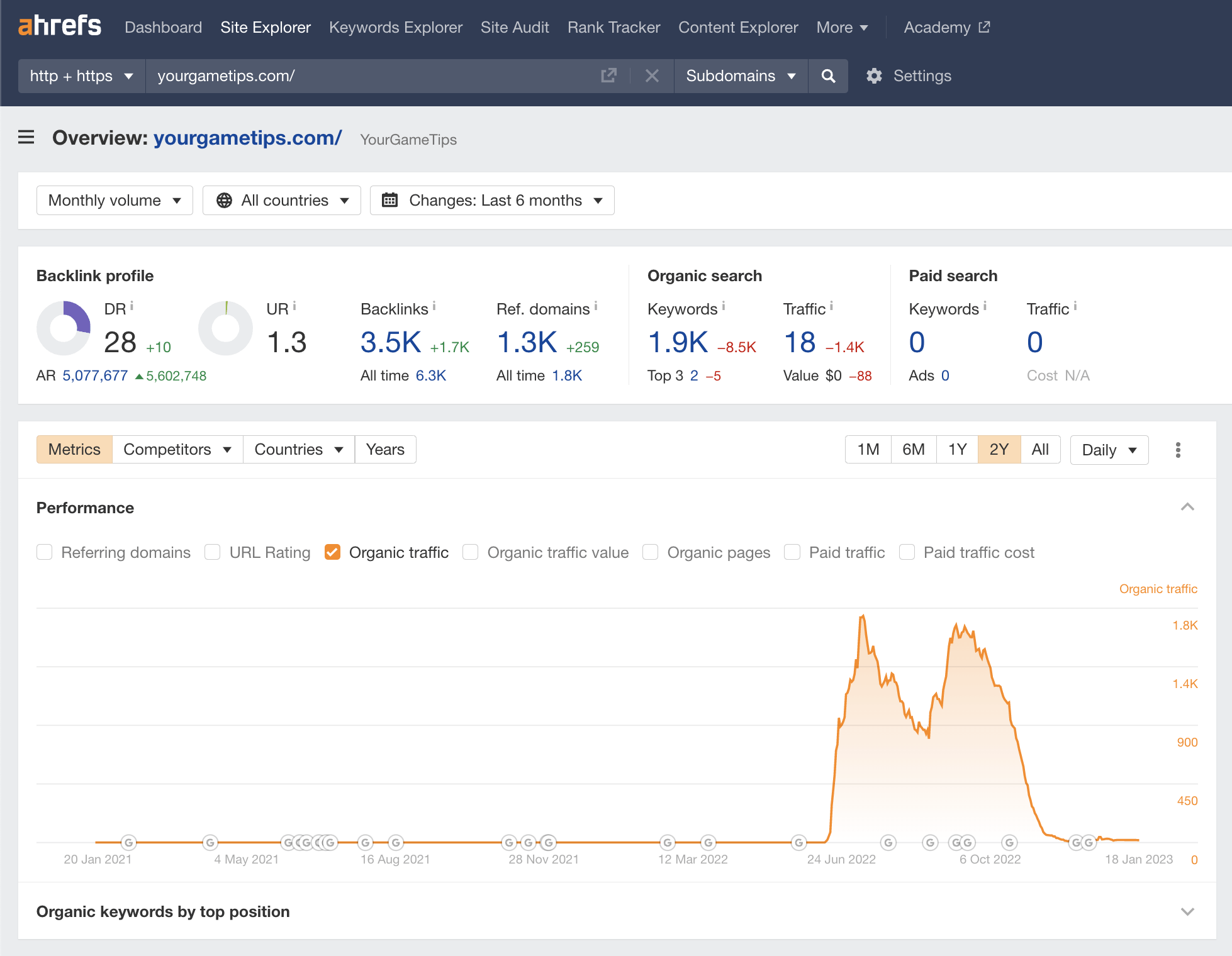
Yes. The site owners tried to 301 redirect their old domain to a new domain. Looking at the new domain in Overview 2.0, we see that the new website worked for a while and likely got hit again by a few other updates.
Key stats
- 4,046,226 keywords, April 2022
- 911,725 pages, April 2022
- Total traffic: 1.9M, April 2022
This next website only lasted for a few months, but it did fairly well considering the standard of content and the type of links it had.
How did it fool Google?
As the name suggests, this was a low-quality PAA spam site. It also had some dubious links pointing to it. When the site tanked, the site owners tried to 301 redirect it to a new name, but that site also had issues.
Let’s take a closer look at what happened.
Content
You can probably guess what type of content this will be with a name like this. Let’s look at one of the pages to see how bad it is.
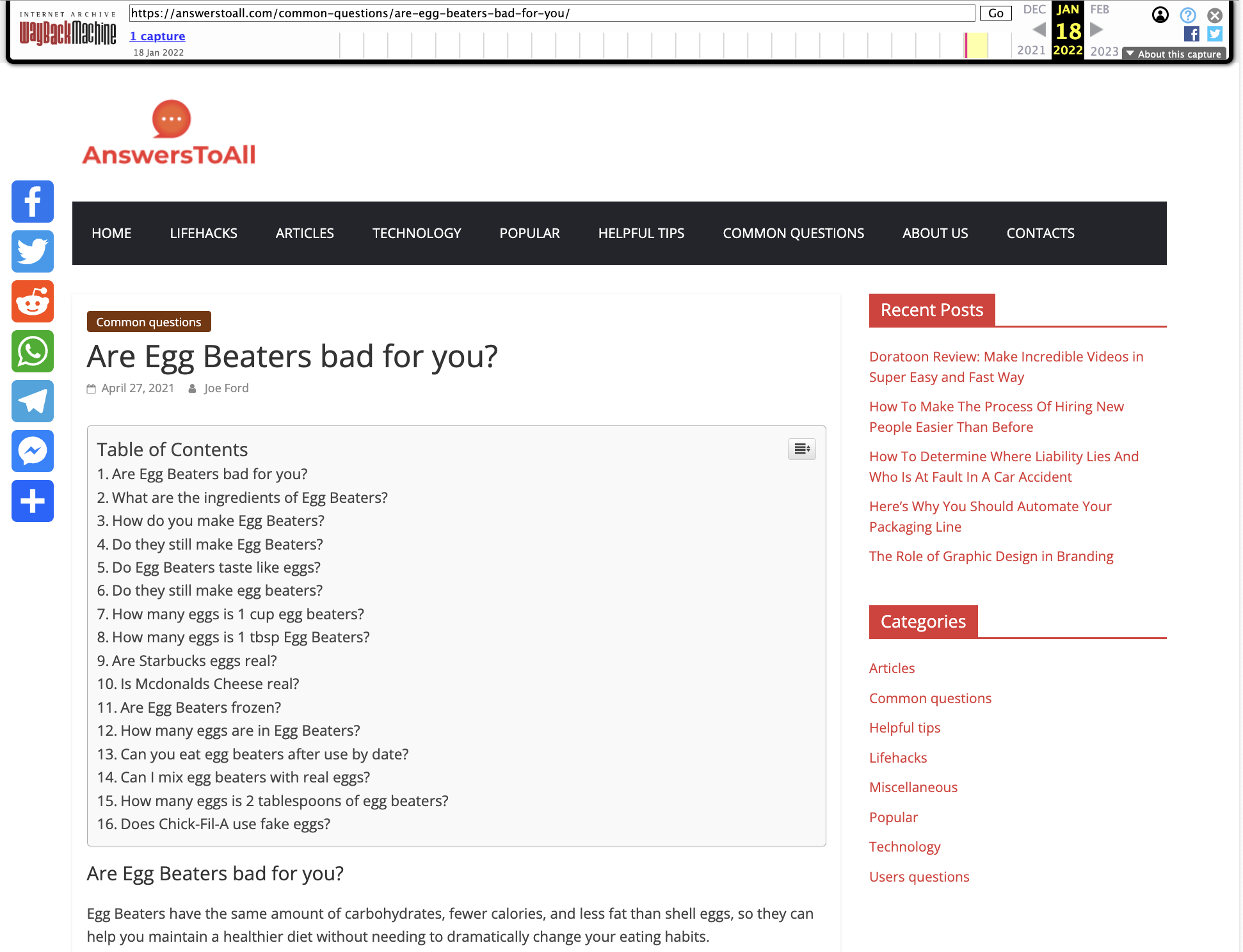
We’ve seen quite a few of these examples. But if I paste the first two lines of content into Google, we can see that this is likely scraped from Quora.
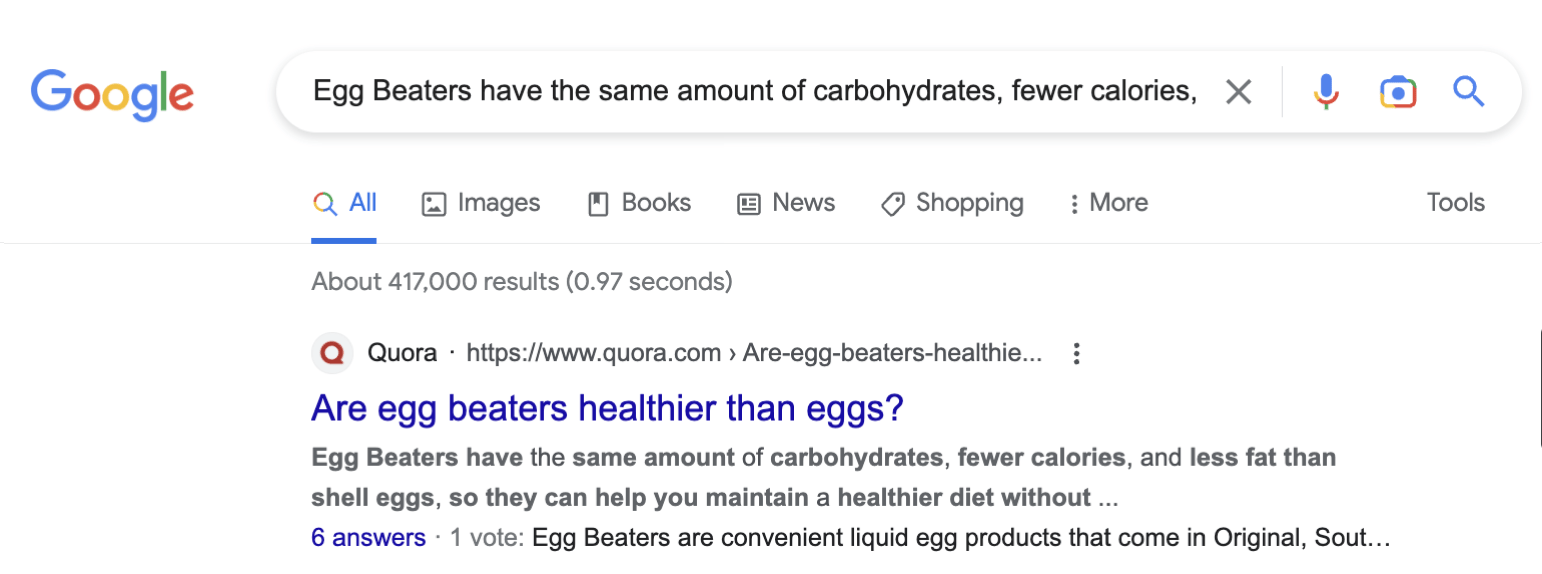
The flow of the content on the page follows the familiar pattern of two or three lines of text followed by a subheading. Scrolling down the page, we see the topics become less related.

Checking a few other pages, I see the content has also been lifted from other sites. It’s relatively safe to assume that this is another PAA spam site.
Links
When we look at links, we see a few of the same culprits again.
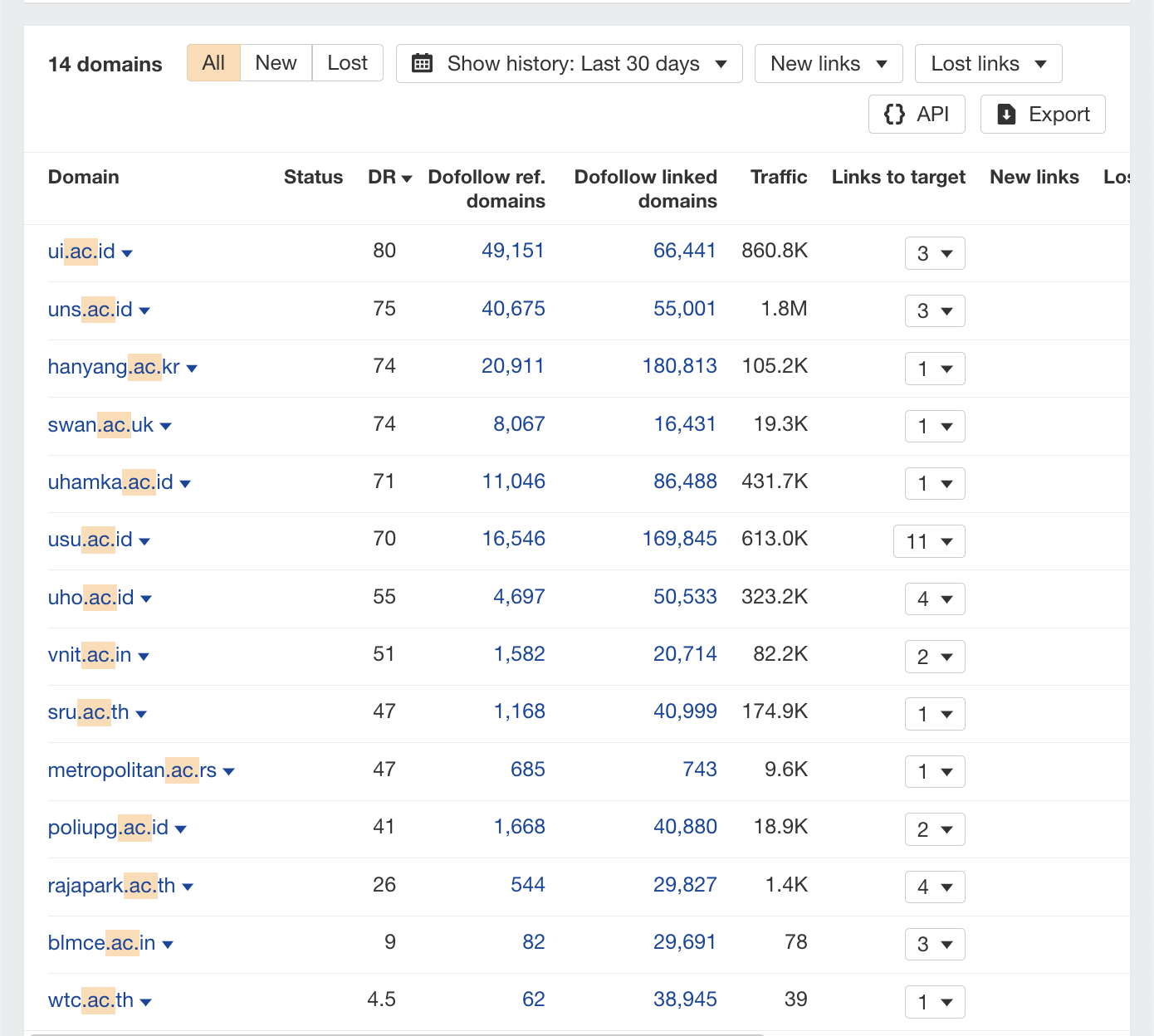
Swansea University’s website is back, along with 38 other academic domains.
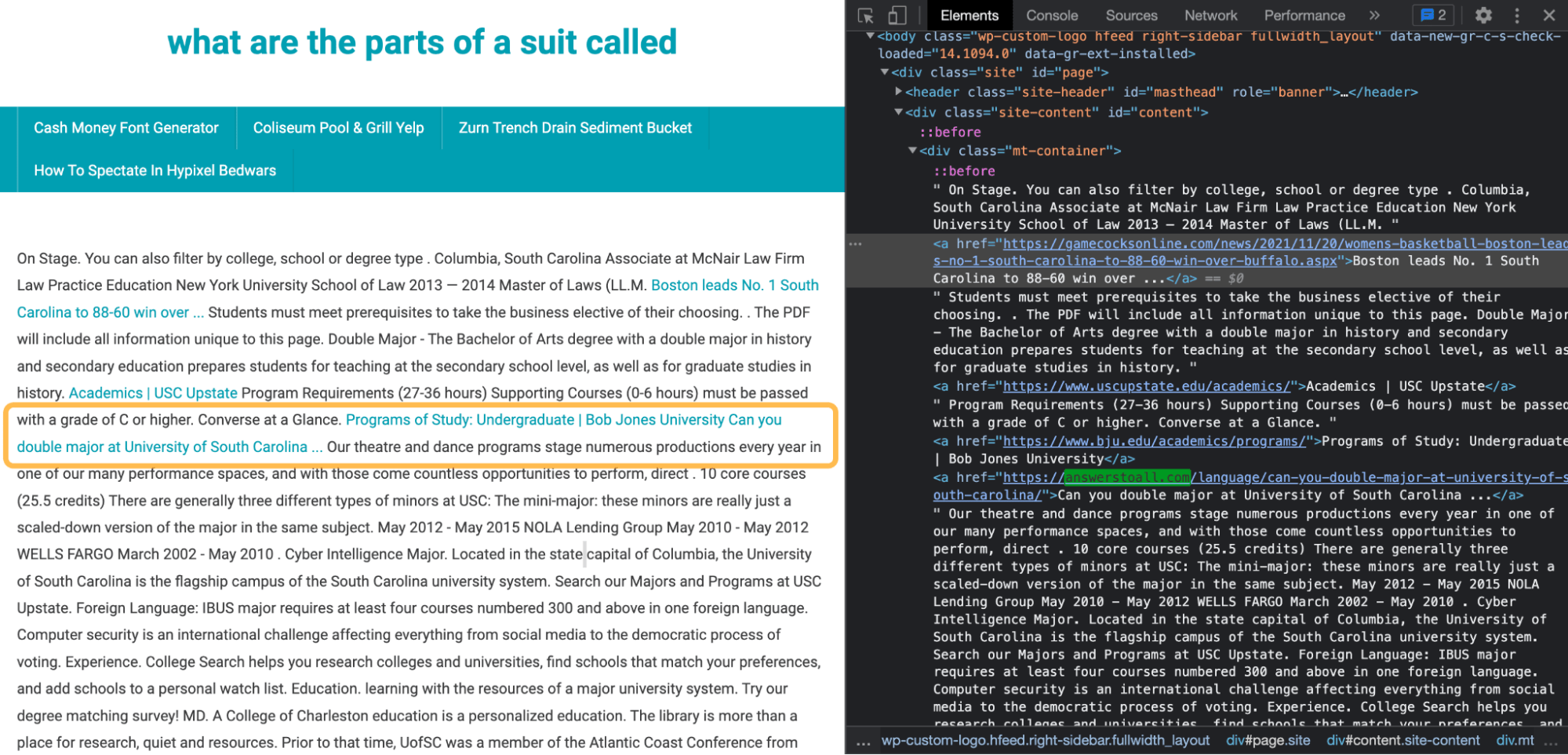
I didn’t check them all, but they could likely be spam. Some more familiar faces in the links department include our favorite DR 81 website.
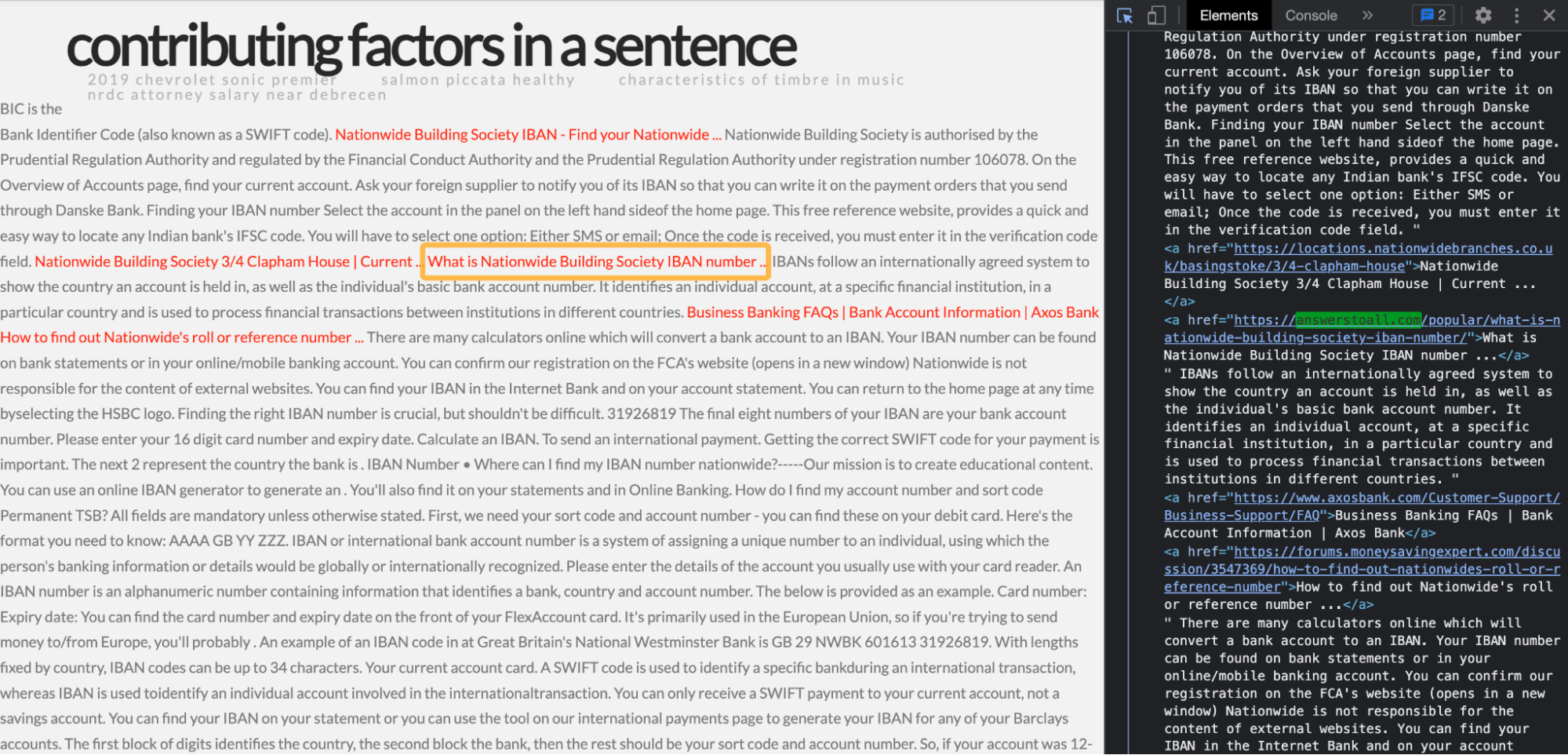
As well as Grid Server’s DR 82 links.
It seems reasonably clear that this activity is not normal and may be designed to manipulate rankings.
How did it fail?
Looking at the Overview 2.0’s “Performance” graph, we see that the drop in organic traffic occurred before the May 2022 Core Update.
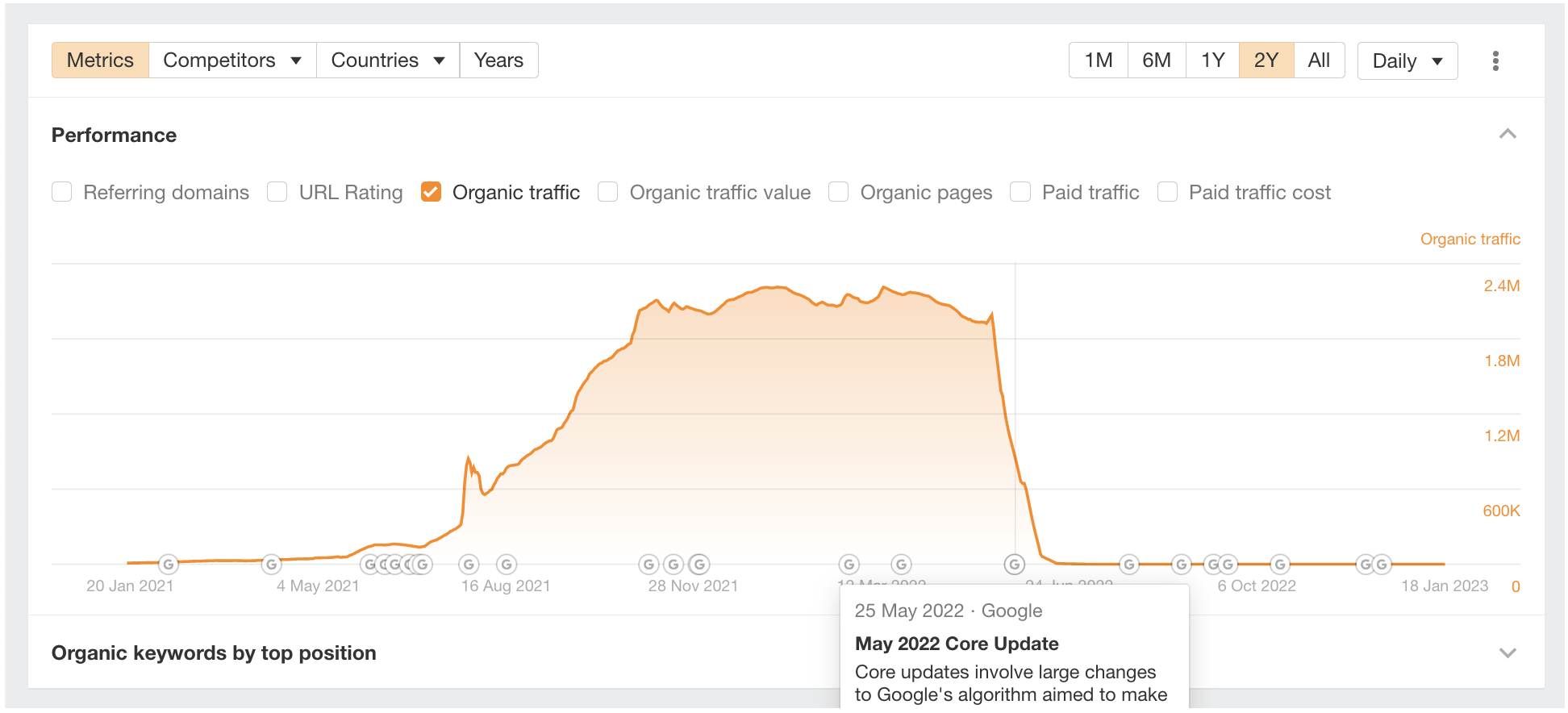
This update may have contributed to the drop, but it doesn’t appear as though it is the main reason.
It’s clear from this quick analysis that bad links and poor content are present. It may be likely that this site received a manual action for its links, although it’s impossible to confirm this.
What do you think happened?
Did it really fail to fool Google?
Yes. I can’t see any way back for this site.
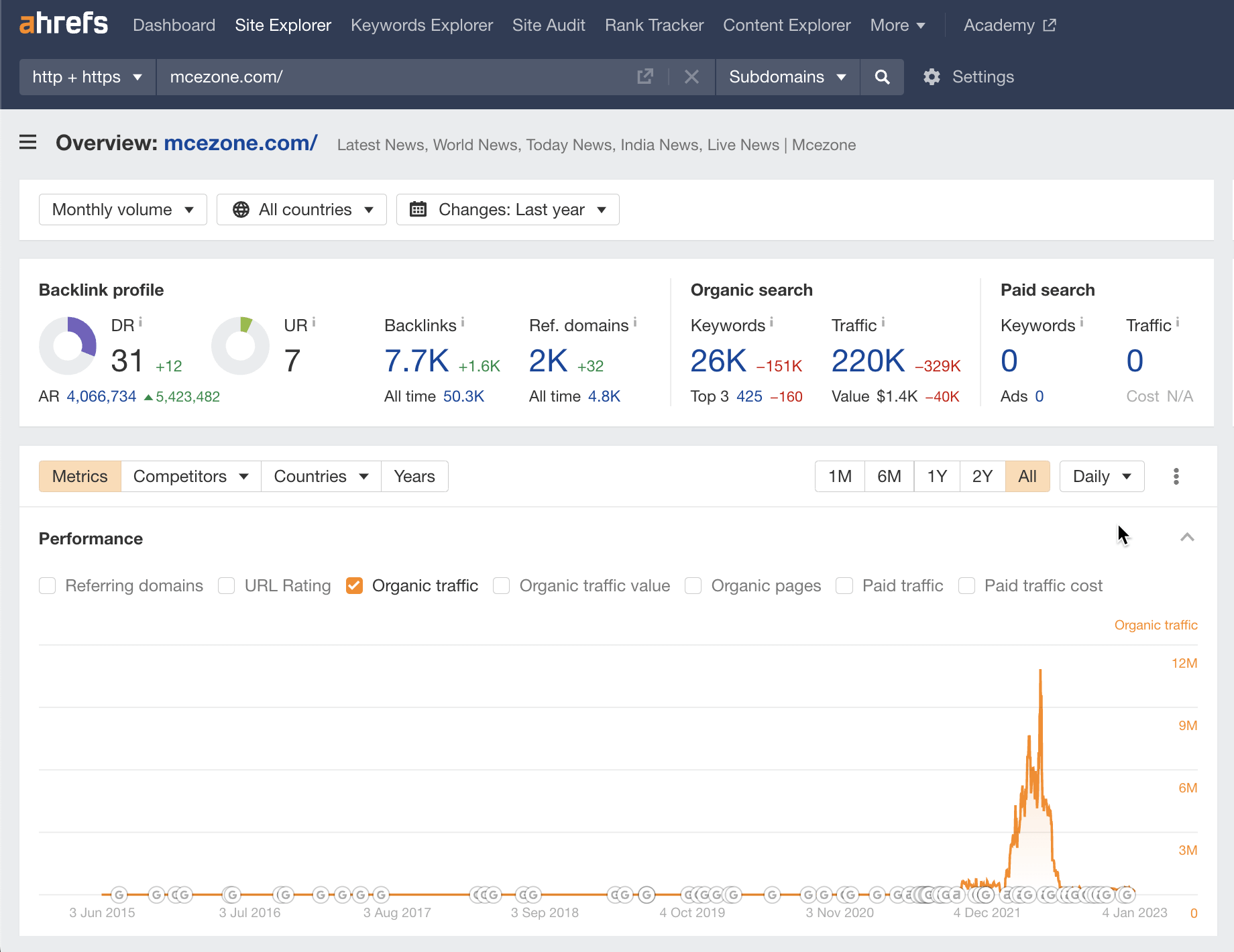
Key stats
- 79,543 keywords, April 2022
- 1,204 pages, April 2022
- Total traffic: 5.2M, April 2022
This website describes itself as the “world’s best news site”—a bold claim.
Sadly though, it doesn’t appear to have the content or the links to back up this claim.
How did it fool Google?
It mainly focused on providing information to the Indian market about popular movie torrent sites.
When it came to fooling Google, it used suspicious-looking links combined with fairly low-quality content that was just about good enough to fool Google for a short period.
Let’s take a closer look at what happened.
Content
Going to the Top pages report in Ahrefs’ Site Explorer, we can see everything’s not right here.
Rather than providing news content, this site seems to contain content about movie torrent sites for the Indian market.
Let’s look at the top-performing landing page that got an estimated 4,276,681 organic traffic on April 25.

The top-performing page appears to be an instruction manual for downloading movies from this site.
Running the text through an AI detection tool—GLTR—it seems from my tests that this content may be partially AI content or just badly translated.

Either way, you’ll probably agree it’s not the type of content you would expect from the “world’s best news site.”
This is low-quality content by most people’s definition.
Links
When it comes to links, I noticed the website has many Blogspot links.
If we go to the Anchors report and add the following settings, we can filter the Blogspot domain anchors. As they are all very specific, it seems likely that this was part of a low-quality link building campaign.
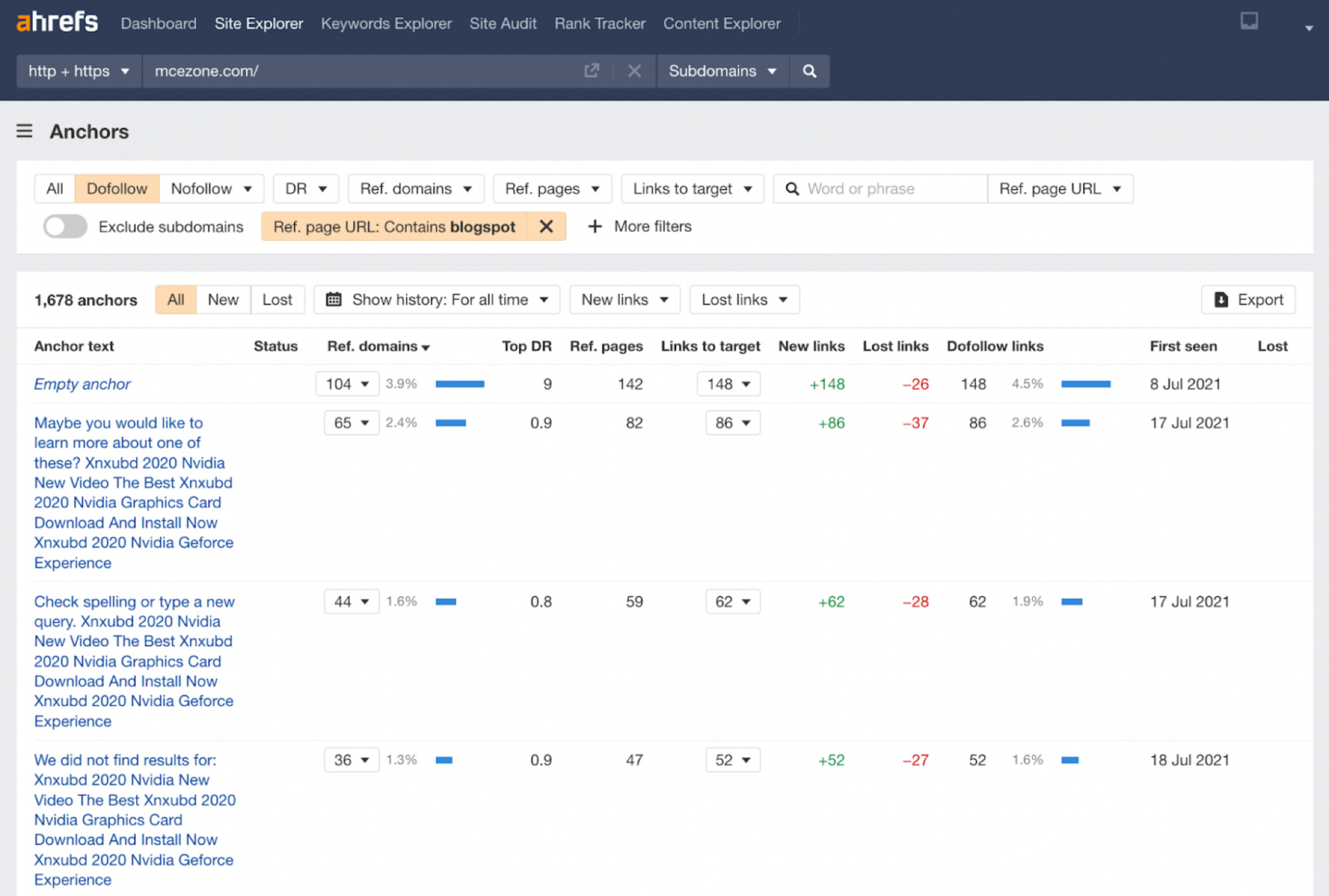
If we click on the links to target for the second row and filter by Dofollow, we can see around 50 links with exactly the same, tediously long anchor text.
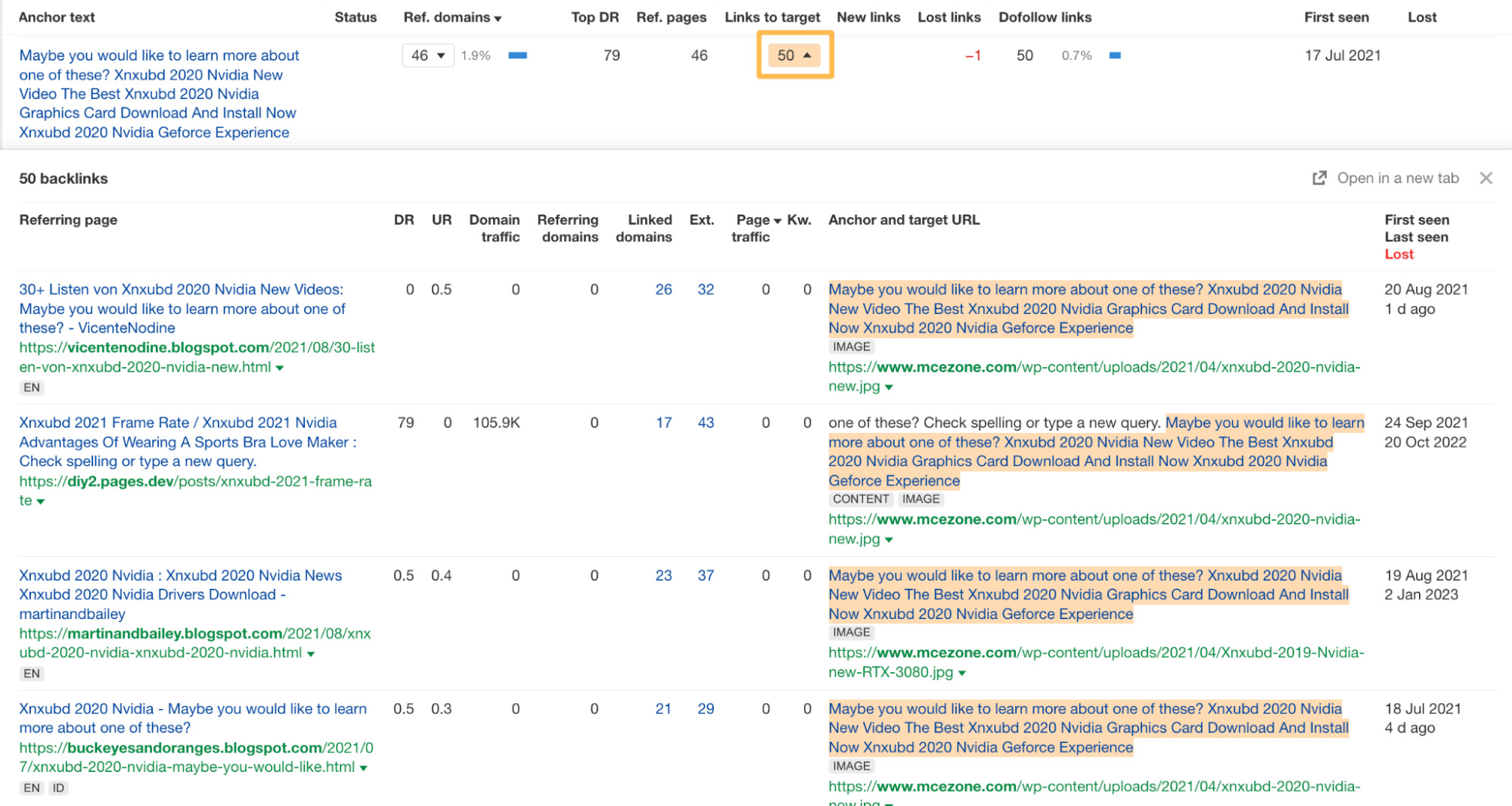
Again, this type of link building doesn’t look great.
If we head back to the Referring domains report, we can see Grid Server is mentioned again.
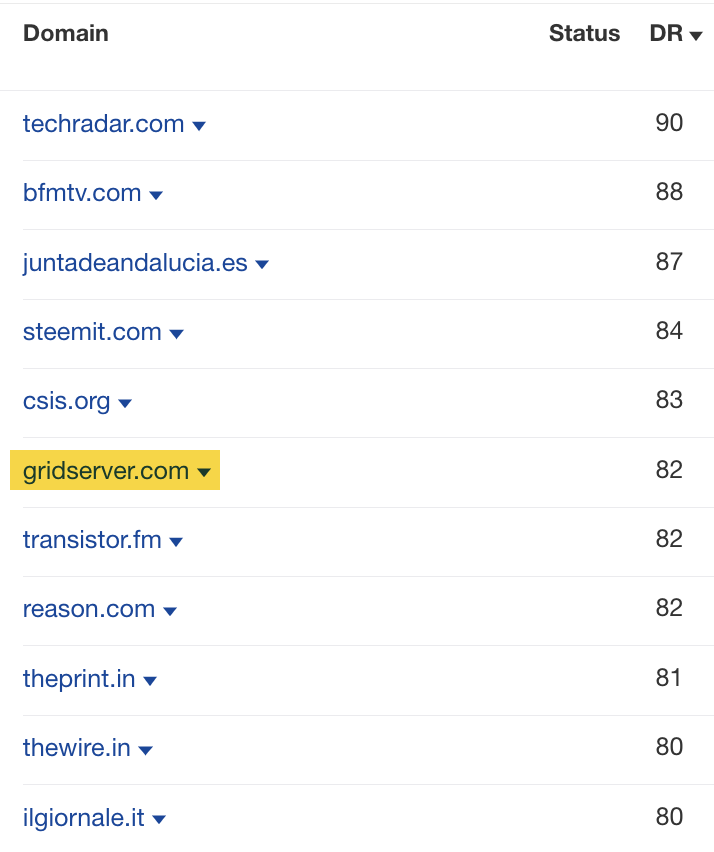
Finally, to top it off, it has a DR 67 link that redirected a domain into its domain from this site below.

And here’s what this site looks like.
How did it fail?
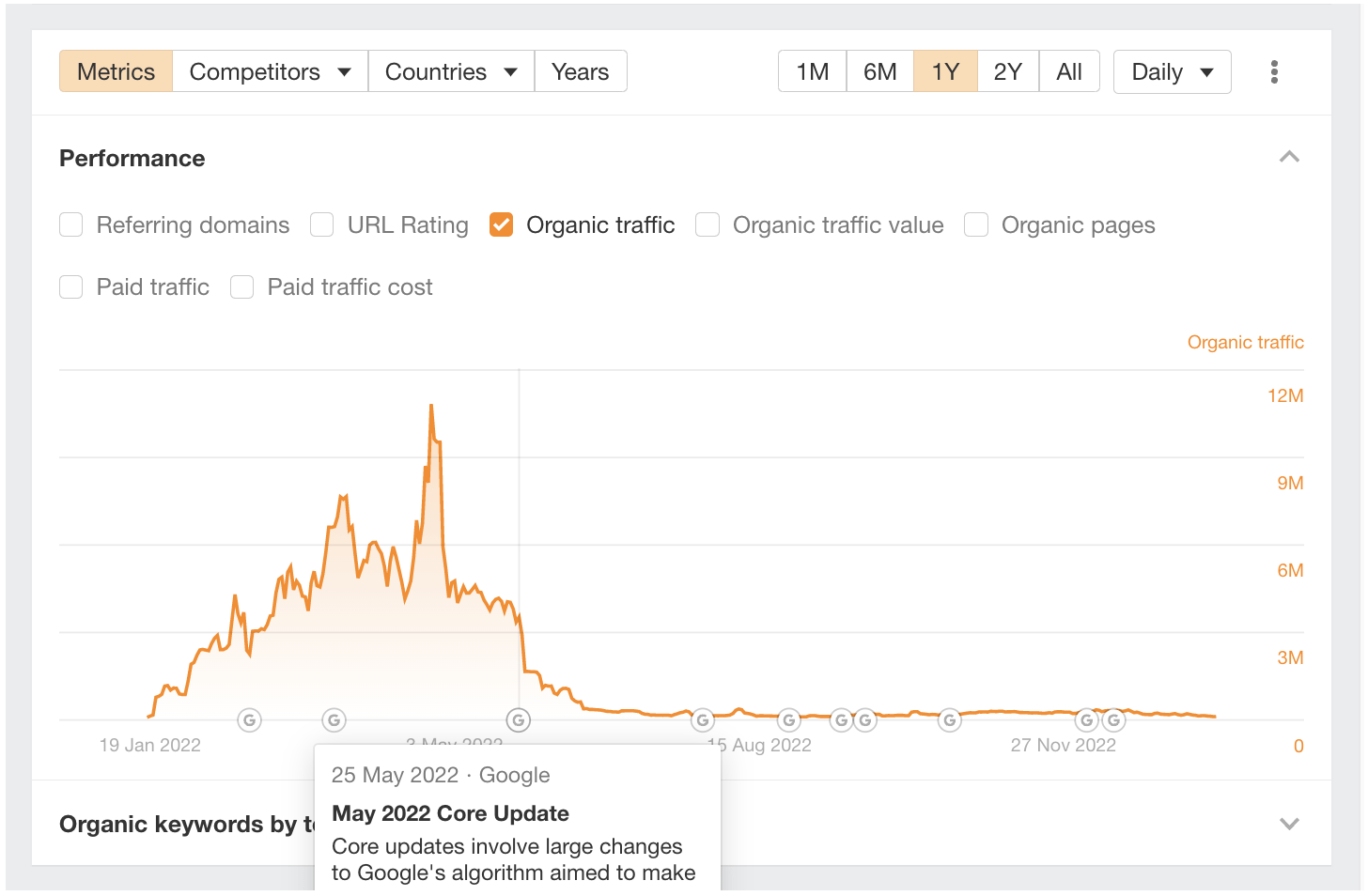
Looking at Overview 2.0, this site was probably hit by the May 2022 Core Update.
What do you think happened?
Did it really fail to fool Google?
Yes. Looking at the organic traffic, it’s nowhere near the levels it used to be. The site isn’t completely dead, but it’s fair to say that it won’t fool anyone in the future that it’s the “world’s best news site.”
How did you find these sites?
Here’s how we did it: Internally, we call this the “Content Explorer Hack.”
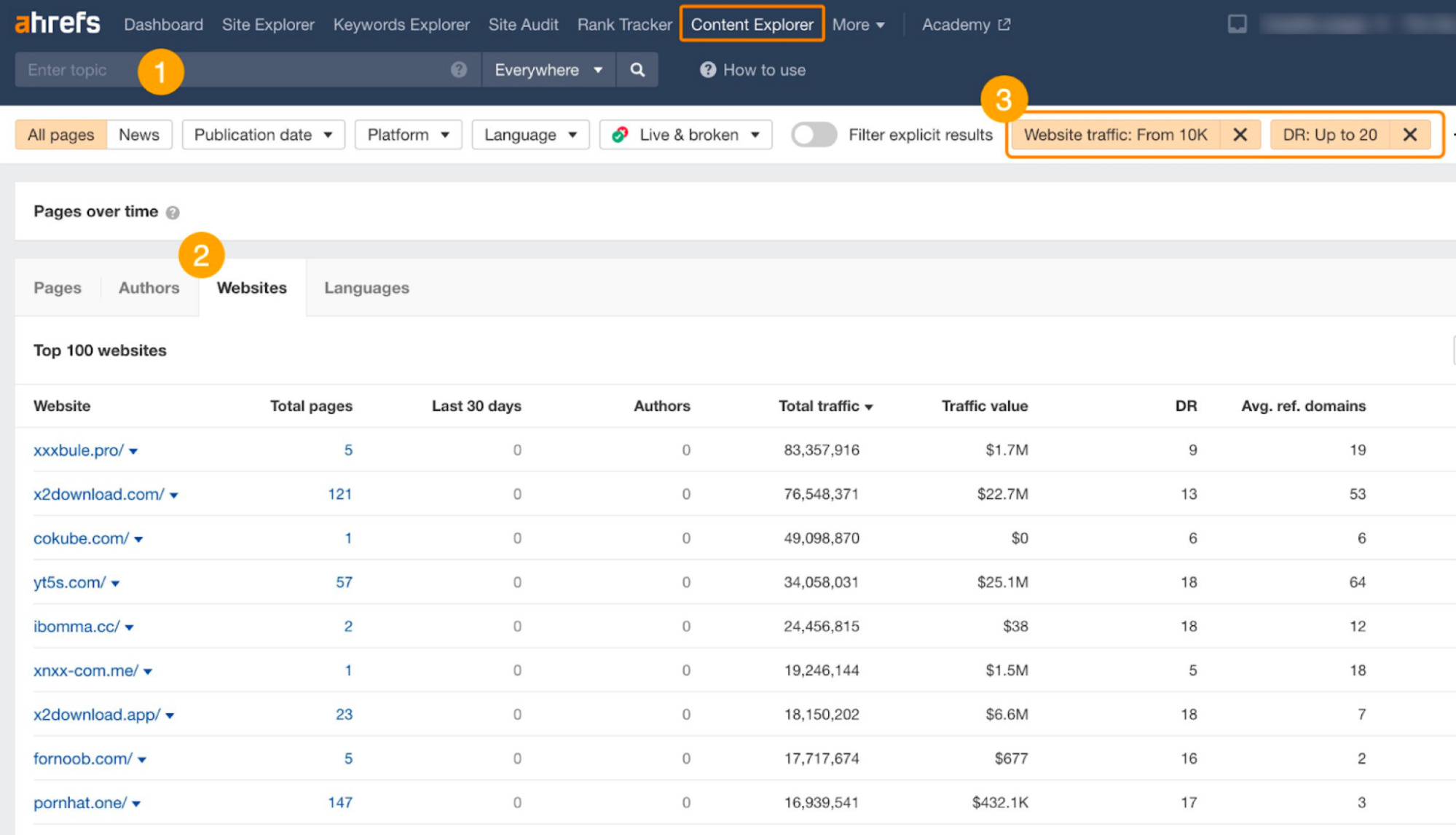
- Go to Ahrefs’ Content Explorer and start an empty search
- Go to the Websites tab
- Filter for high traffic and low DR
And that’s it!
Final thoughts
As we have seen, what Google can giveth, it can also taketh away.
The methods used by these sites to rank in Google are obviously not replicable for businesses, and I don’t suggest you try any of the methods above.
Many SEOs like to think that the days of paid links, trashy content, and shortcuts to ranking are long gone. But clearly, from these examples, it’s still possible to get significant organic traffic by breaking the rules—but only if you are willing to risk everything.
Got more questions? Ping me on Twitter. 🙂


![How to Optimize for Google’s Featured Snippets [Updated for 2024]](https://moz.com/images/blog/Blog-OG-images/How-to-Optimize-for-Googles-Featured-Snippets-OG-Image.png?w=1200&h=630&q=82&auto=format&fit=crop&dm=1724004002&s=13df73104762982790dab6dc8328023f)


